This post is going to be a sort of a follow up to my ELK 5 on Ubuntu 16.04 series. I am going to cover some of the lessons I have learned over the last few months of maintaining a running ELK stack instance. I am also going to cover some one liners that can be very helpful in troubleshooting and checking the health of the Elasticsearch service.
Here is the quick run down of my setup:
- Elasticsearch, Logstash and Kibana on Single Node (No cluster or replicas)
- 15 Windows and Linux machines sending logs via Filebeat and/or Winlogbeat
- 2 mo. retention policy
- Total storage used is generally between 100-200GB
Note that some of the tweaks (like the replicas) I am going to talk about here are needed because of the fact that I am only running 1 Elasticsearch node. For example the default Elasticsearch configuration is to have 2 replicas, but with only 1 node this is not possible and will lead to unassigned shard issues. If this were a production setup you would want to leave this setting or even increase it and add in additional nodes.
Elasticsearch Health Status
To check the health status of Elasticsearch, run the following command on the server running the Elasticsearch service:
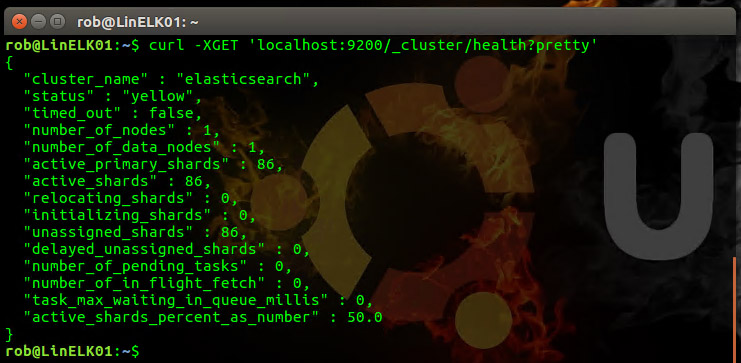
$ curl -XGET 'localhost:9200/_cluster/health?pretty'
You should see something similar to the following returned:
rob@LinELK01:~$ curl -XGET 'localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "yellow", <-------------------
"timed_out" : false,
"number_of_nodes" : 1, <-----------------
"number_of_data_nodes" : 1,
"active_primary_shards" : 86,
"active_shards" : 86,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 86, <--------------
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
There are a few important things to note in this output:
- The status is yellow
- There are 86 shards assigned and 86 unassigned
Remember when I said that the default Elasticsearch config is to have 2 replicas? Notice how the number assigned shards matches the number of unassigned, this is happening because Elasticsearch is trying to replicate to another node but there isn't one in this case. This is also the reason why the status is yellow. I'll show you how to fix this later in the post, but for now let's take a look at a few other things.
More info about cluster health can be found here:
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-health.html
Checking the Elasticsearch Shards
Each indice will have a number of shards associated with it, use the following command to check the shards and their status:
$ curl -XGET 'localhost:9200/_cat/shards?pretty'
You should see something similar in the output:
rob@LinELK01:~$ curl -XGET 'localhost:9200/_cat/shards?pretty' filebeat-2017.04.13 2 p STARTED 762 233kb 127.0.0.1 AjnlVN6 filebeat-2017.04.13 2 r UNASSIGNED filebeat-2017.04.13 4 p STARTED 779 205.1kb 127.0.0.1 AjnlVN6 filebeat-2017.04.13 4 r UNASSIGNED filebeat-2017.04.13 1 p STARTED 765 249.6kb 127.0.0.1 AjnlVN6 filebeat-2017.04.13 1 r UNASSIGNED filebeat-2017.04.13 3 p STARTED 757 239.6kb 127.0.0.1 AjnlVN6 filebeat-2017.04.13 3 r UNASSIGNED filebeat-2017.04.13 0 p STARTED 777 200kb 127.0.0.1 AjnlVN6 filebeat-2017.04.13 0 r UNASSIGNED winlogbeat-2017.04.15 2 p STARTED 73 211.4kb 127.0.0.1 AjnlVN6 winlogbeat-2017.04.15 2 r UNASSIGNED winlogbeat-2017.04.15 4 p STARTED 80 221.7kb 127.0.0.1 AjnlVN6 winlogbeat-2017.04.15 4 r UNASSIGNED winlogbeat-2017.04.15 3 p STARTED 63 240.3kb 127.0.0.1 AjnlVN6 winlogbeat-2017.04.15 3 r UNASSIGNED winlogbeat-2017.04.15 1 p STARTED 64 186.7kb 127.0.0.1 AjnlVN6 winlogbeat-2017.04.15 1 r UNASSIGNED winlogbeat-2017.04.15 0 p STARTED 67 199.9kb 127.0.0.1 AjnlVN6 winlogbeat-2017.04.15 0 r UNASSIGNED filebeat-2017.04.01 4 p STARTED 373 111.3kb 127.0.0.1 AjnlVN6 filebeat-2017.04.01 4 r UNASSIGNED filebeat-2017.04.01 2 p STARTED 378 107.2kb 127.0.0.1 AjnlVN6 filebeat-2017.04.01 2 r UNASSIGNED filebeat-2017.04.01 3 p STARTED 357 103.9kb 127.0.0.1 AjnlVN6 filebeat-2017.04.01 3 r UNASSIGNED filebeat-2017.04.01 1 p STARTED 353 101.4kb 127.0.0.1 AjnlVN6 filebeat-2017.04.01 1 r UNASSIGNED filebeat-2017.04.01 0 p STARTED 379 111.1kb 127.0.0.1 AjnlVN6 filebeat-2017.04.01 0 r UNASSIGNED filebeat-2017.05.09 4 p STARTED 376 110.7kb 127.0.0.1 AjnlVN6 ...
Notice the column containing the letters p and r, this stands for primary and replica, as you can see all of the replicas are currently unassigned since there is no node to assign them to. To the left of that column, you can also see the shard # and how many there are, in this case there are 5 shards per indice which is the default for Elasticsearch.
More info can be found here:
https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-shards.html
Set the Logstash Output to yyyy.ww Vs YY.MM.dd to Limit the Shard Count
After the ELK instance has been up and recieving logs for a few months, you may run into issues with Elasticsearch or Kibana giving errors about too many shards. This will eventually cause the Elasticsearch service to fail, and show a status of red. Kibana will also fail to load at this point. If you followed my ELK series and this happens, try changing the output to Elasticsearch to yyyy.ww instead of YY.MM.dd in the logstash config. You can find this configuration file referenced in my post, ELK 5 on Ubuntu: Pt. 2 – Installing and Configuring Elasticsearch, Logstash, Kibana & Nginx, on Step 7 under the Installing Logstash section. In this case the configuration file is 30-elasticsearch-output.conf.
output {
elasticsearch {
hosts => ["localhost:9200"]
sniffing => true
manage_template => false
index => "%{[@metadata][beat]}-%{+yyyy.ww}"
document_type => "%{[@metadata][type]}"
}
}
This is an important setting to note and is easily overlooked. Over time as the server continues to collect logs and create new indices automatically, you can end up with too many shards for Elasticsearch. Generally you want to the number of total shards to be less than 1000.
Looking at the shard output from above, you'll notice that the naming convention for each indice with the YY.MM.dd config is as follows:
filebeat-2017.01.01
filebeat-2017.01.02
filebeat-2017.01.03
filebeat-2017.01.04
filebeat-2017.01.05
filebeat-2017.01.06
filebeat-2017.01.07
By changing the config to yyyy.ww, all 7 of those indices would be 1 (weekly) indice:
filebeat-2017.01
With the configuration set to YY.MM.dd, this tells Elastic search to create a new indice everyday and each indice will have 5 shards (default) assigned to it. So let's say we have 30 days worth of data:
| 30 Winlogbeat indices (1 per day) | x 5 shards (per indice) | = 150 |
That doesn't sound too bad, but what if you are storing Winlogbeat, Filebeat, Metricbeat, Packetbeat, and any other data you may have in their own indices? Now how many shards are we looking at?
| 30 Winlogbeat indices (1 per day) | x 5 shards (per indice) | = 150 |
| 30 Filelogbeat indices (1 per day) | x 5 shards (per indice) | = 150 |
| 30 Metriclogbeat indices (1 per day) | x 5 shards (per indice) | = 150 |
| 30 Packetbeat indices (1 per day) | x 5 shards (per indice) | = 150 |
| Total shards: | 600 |
That added up pretty quickly but is still low enough. However, if we were to decide to store 60 days worth of logs instead of just the 30 days that would put us at 1200 shards total and now we have an issue.
This is exactly what happened to me when I started storing more than a month worth of logs on my instance. When you get over 1000+, Elasticsearch will begin to slow down, and if the instance isn't allocating shards correctly (ie unassinged shards) the elastic instance will fail and set the status to red.
More info on the date formats can be found here:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html#built-in-date-formats
Changing the Number of Replicas
If you find out that you have unassigned indices due to replicas, you can force the number of replicas to match your environment. In this case, with just a single node, I do not want any replicas.
Checking the Elasticsearch service health we see the following:
rob@LinELK01:~$ curl -XGET 'localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "yellow", <-------------------
"timed_out" : false,
"number_of_nodes" : 1, <-----------------
"number_of_data_nodes" : 1,
"active_primary_shards" : 86,
"active_shards" : 86,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 86, <--------------
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
Now run the following command on the Elasticsearch server to update all existing indices:
$ curl -XPUT 'localhost:9200/_settings?pretty' -H 'Content-Type: application/json' -d'
{
"settings" : {
"index" : {
"number_of_replicas" : 0
}
}
}
'
You should see something similar in the output:
rob@LinELK01:~$ curl -XPUT 'localhost:9200/_settings?pretty' -H 'Content-Type: application/json' -d'
> {
> "settings" : {
> "index" : {
> "number_of_replicas" : 0
> }
> }
> }
> '
{
"acknowledged" : true
}
rob@LinELK01:~$
Recheck the servers health status and verify that the status is now green and there are no unassigned shards:
rob@LinELK01:~$ curl -XGET 'localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elasticsearch",
"status" : "green", <--------------------
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 91,
"active_shards" : 91,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0, <---------------
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Perfect! Everything looks to be on point...Until a week later, and you find out that there are new unassigned shards because the new indices are created using the Elasticsearch defaults of 2 replicas. To overcome this, a template will need to be created with the desired configuration.
Using Templates to Define the Number of Replicas
Use the following command to set the number of replicas on all templates to match the number of Elasticsearch nodes, which in this case I only have the 1 so I am setting the replicas to 0:
curl -XPUT 'localhost:9200/_template/default' -d '
{
"template" : "*",
"settings" : {"number_of_replicas" : 0 }
} '
And you should see something similar in the output:
rob@LinELK01:~$ curl -XPUT 'localhost:9200/_template/default' -d '
> {
> "template" : "*",
> "settings" : {"number_of_replicas" : 0 }
> } '
{"acknowledged":true}
rob@LinELK01:~$
All new indices should now be created without replicas and there should not be anymore unassigned shards moving forward.