Intro & Background
It seems safe to say that artificial intelligence (AI), particularly large language models (LLMs), are here to stay. As a cybersecurity professional, it has been pretty easy to find use cases for AI in my daily work, from general penetration testing and writing tools to forensics and reverse engineering. However, as with any cloud-based solution, privacy is a major concern, particularly when handling sensitive cyber information. This was the main issue holding me back from fully embracing AI.
The open-source AI landscape has seen significant progress over the last year, so I figured it was finally time to invest in some hardware and see if I could find a solution that works for me. Initially, I set out to find a back end for hosting LLMs, a front end for chat, and then likely look into building my own agents/tools (scrapers, scanners, etc) and orchestration solutions to handle stuff like Retrieval-Augmented Generation (RAG).
After evaluating several solutions, I found that Ollama and Open WebUI were the ultimate combination that I was looking for, offering a great deal of flexibility and extensibility while still being easy to use.
Post Outline & Goals
For the sake of brevity, I’m going to assume you have a basic understanding of AI and LLMs. For example, I won’t be explaining the history or theory behind generative AI, but I will do my best to add relevant context when needed. My goal is to give you all the details, commands, and tips needed to get your own dedicated local AI host up and running reliably in the shortest amount of time possible. The end result will be a web based chat setup with RAG and web search capabilities that can also be extended with custom tools, functions, and pipelines.
Here is a brief outline of what will be covered:
- Server Hardware
- Ollama
- Installing Ollama
- Managing Ollama
- Choosing Models
- Open WebUI
- Installing Docker
- Nvidia Container Support
- Installing Open WebUI
- Auto Updating With Watchtower
- Basic Usage
- Downloading & Managing Models
- Documents & Knowledge (RAG)
- Embedding Model Engine
- The Context Length Issue
- Chat Uploads
- Knowledge
- Web Search Configuration
- Tools, Functions, & Pipelines
- Host Monitoring
- Cheat Sheets
Server Hardware

Running large language models can get expensive, largely because they require substantial memory. Ideally, you should maximize your CPU, RAM, GPU, and VRAM within your budget. While a GPU isn’t essential, it’s necessary for good performance. If you plan to use a GPU, ensure it’s supported by the software you’re using.
You can find a list of supported GPUs for Ollama here:
https://github.com/ollama/ollama/blob/main/docs/gpu.md
To be frank, while AMD/ATI cards may seem attractive as they offer more budget-friendly options with increased memory, their support is considerably more limited compared to Nvidia cards.
For my setup, I chose a refurbished Dell Precision Tower 5810 (Xeon CPU, 64GB RAM, 500GB SSD), which I found for around $300 US on Amazon. These older engineering workstations are excellent for this kind of project, offering features like server-grade CPUs, large power supplies, multi-GPU support, and extensive memory expandability. I also found an additional 128GB of RAM for about $150 US and a single RTX 4060 Ti 16GB GPU for $450 US, bringing the total cost of my AI rig to ~$900 US.
Here are the detailed specifications:
| Platform | Dell Precision Tower 5810 |
| OS | Ubuntu Server 24.04 |
| CPU | Intel Xeon E5-2630 v4 @ 2.20GHz (10 Cores/20 Threads) |
| GPU | Gigabyte RTX 4060 Ti 16GB |
| Memory | 192GB DDR4 2400MHz ECC (256GB Max) |
| HDD | 2 x 500GB SSDs |
Ubuntu 24.04 is going to be my OS of choice, all commands referenced will reflect this.
Note: For those of you with a keen eye, technically the Ubuntu server in this post is going to be a virtual machine running via ESXi on the Dell Precision and the GPU has been passed through. I did this to simplify building and tearing down the host while I tried different solutions and for this post. Once all testing completed, Ubuntu was installed bare metal.
Ollama
Ollama will serve as the “backend” for this project, hosting all of the LLMs. I’ve found Ollama to be exceptionally easy to use and highly flexible, making it a great choice for development and experimentation. Plus, it’s open-source and free.
You can find more about Ollama here:
https://ollama.com/
Installing Ollama
Downloading and installing Ollama is very straight forward:
https://ollama.com/download
On Ubuntu, you can install Ollama with one simple command:
# curl -fsSL https://ollama.com/install.sh | sh
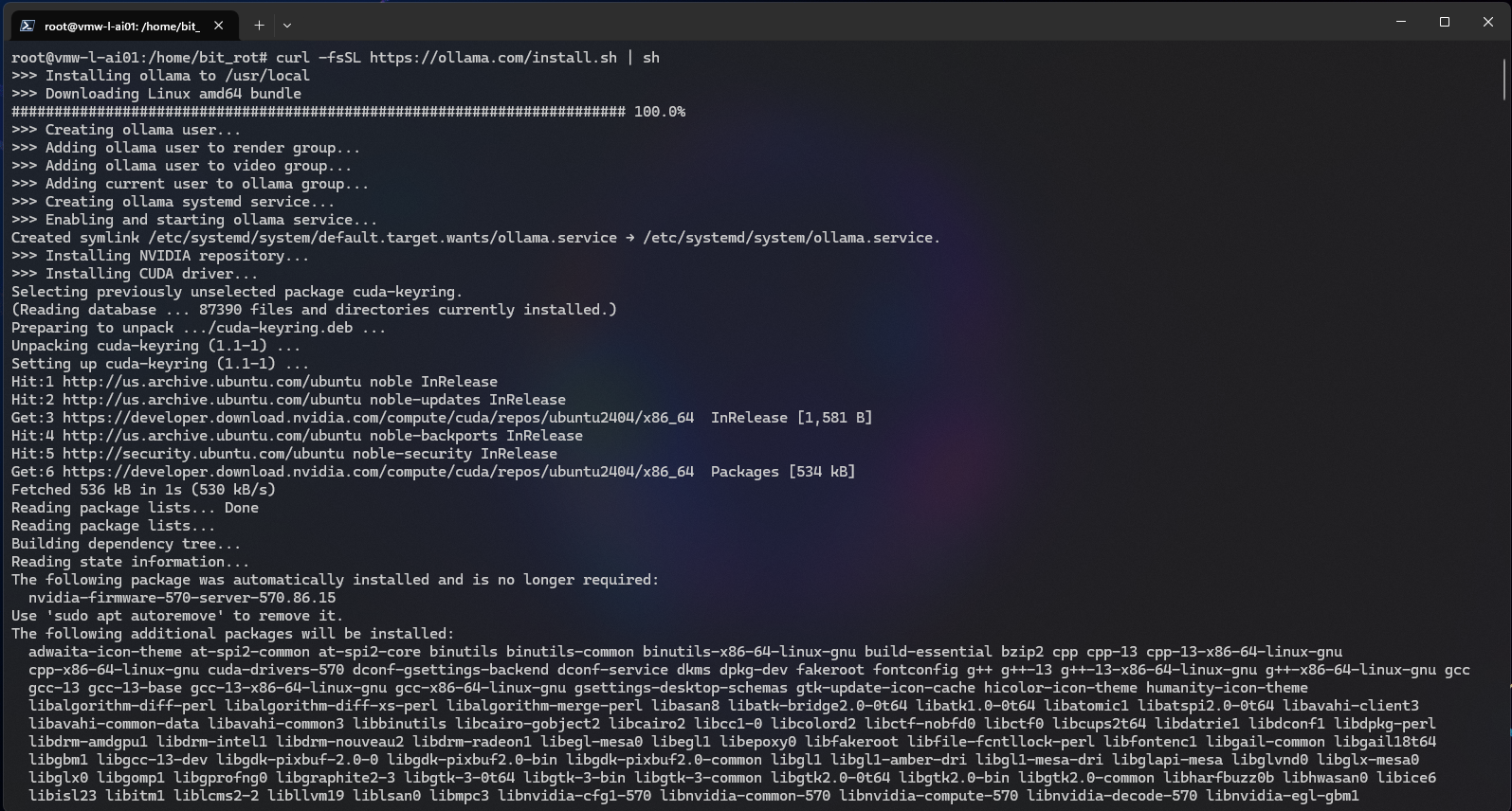
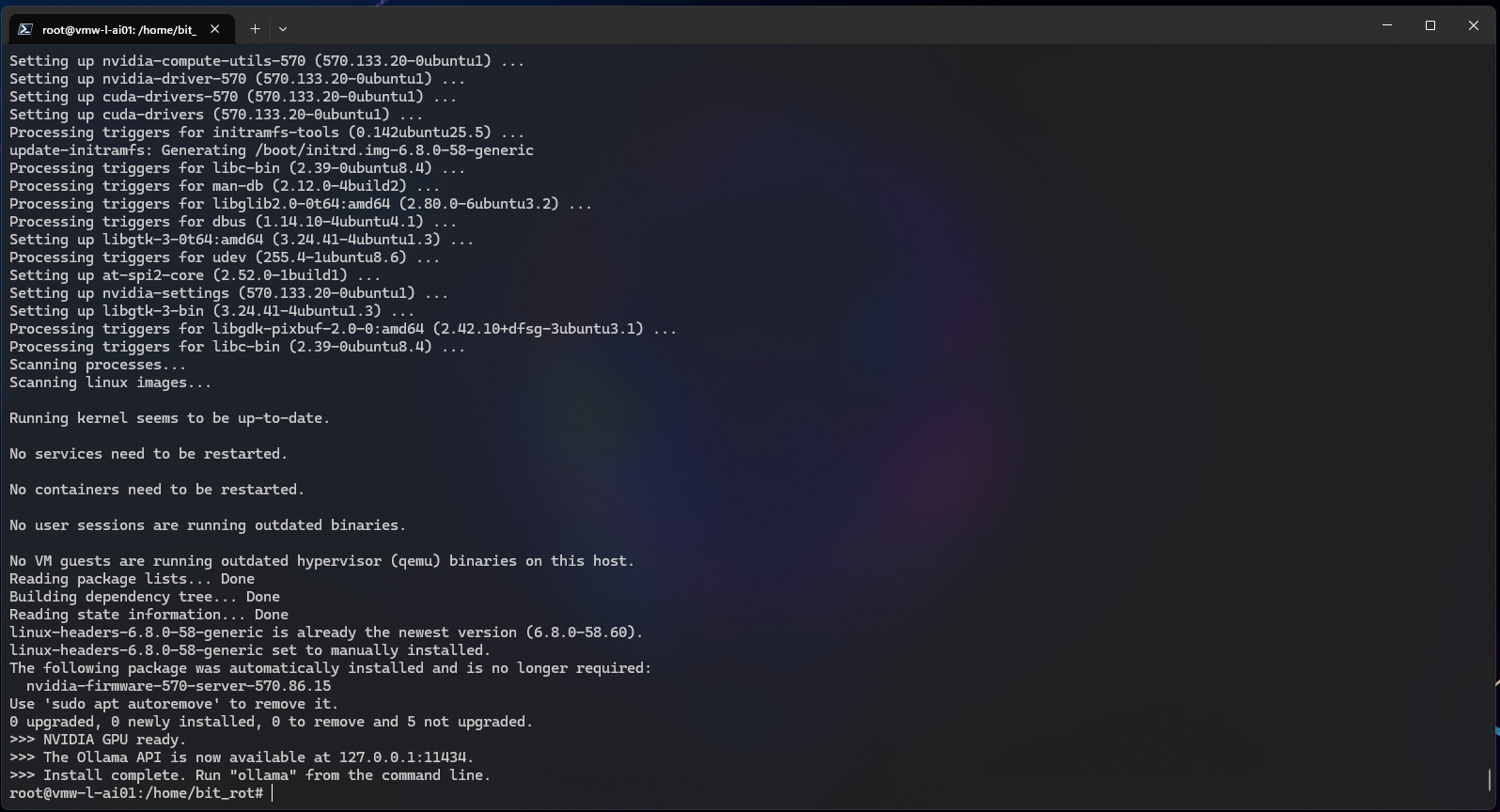
Reviewing the output, it looks like the install was successful with GPU support.
Ollama should now be available at http://127.0.0.1:11434, meaning it should only be accessible from the host it’s running on, let’s take a look:
# ss -antp | grep :11434 # curl http://localhost:11434 -v
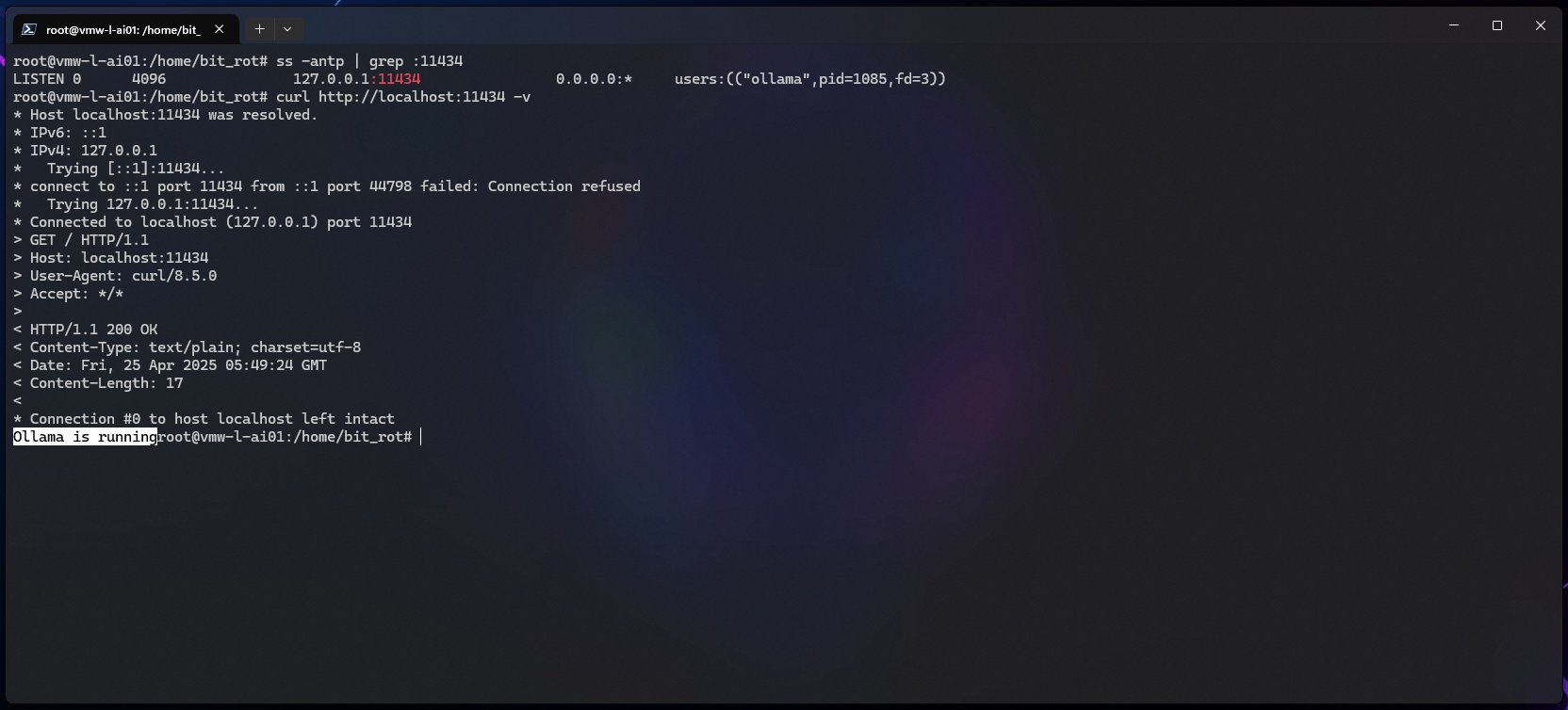
Ollama is now running as a local service and will restart with the system automatically.
Managing Ollama
Running the ollama command with –help provides everything you need to get started:
# ollama --help
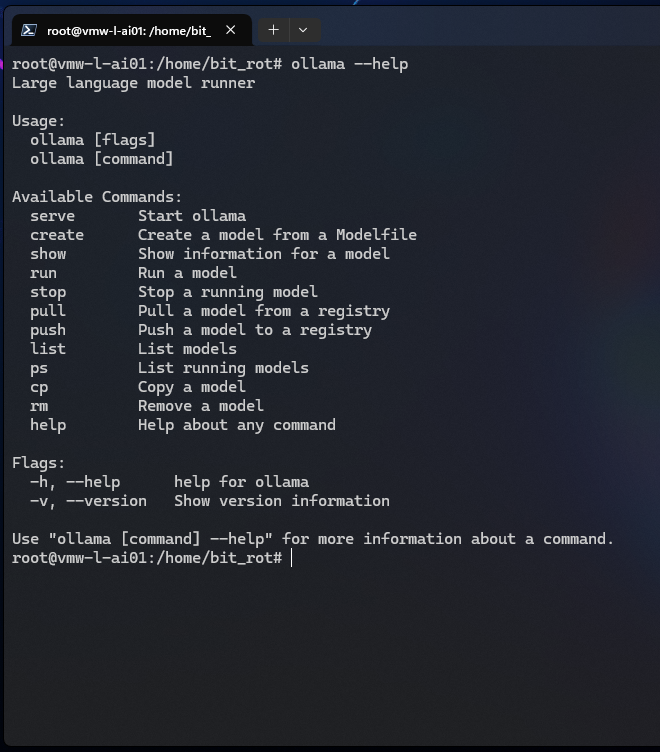
I’ll talk a little but more about how to select a model in the “Choosing Models” section coming up next, but for now this is how to download (or update) a model:
# ollama pull gemma3:1b

List all locally installed models:
# ollama list
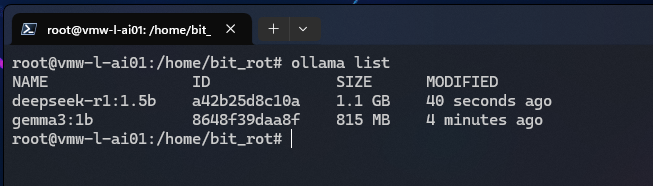
Remove a locally installed model:
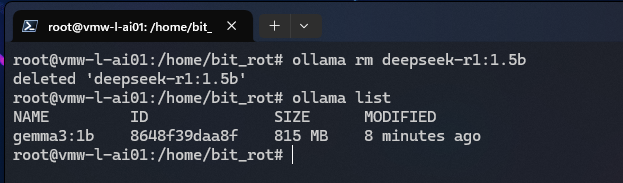
# ollama rm deepseek-r1:1.5b
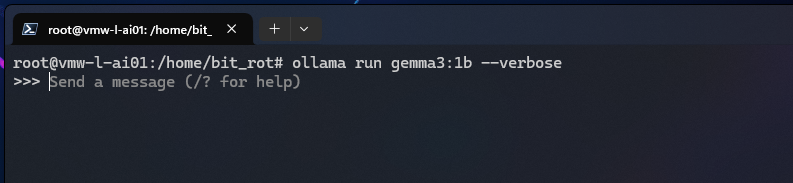
Run a model interactively in the terminal – add in the –verbose parameter to provide some useful additional stats about the session:
# ollama run gemma3:1b --verbose
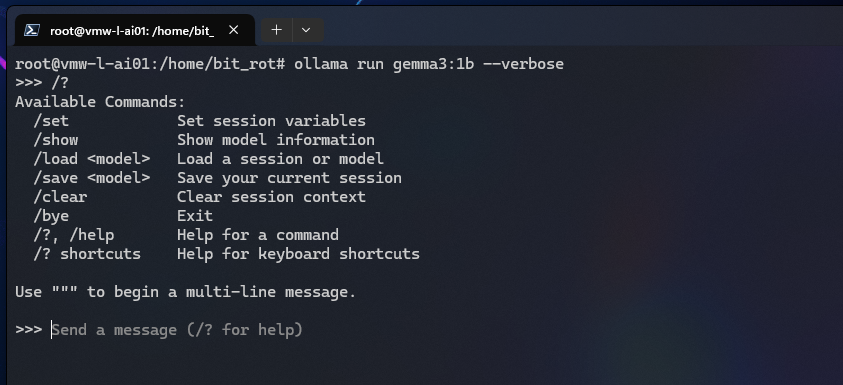
Within the run session, an additional help menu is available:
>>> /?
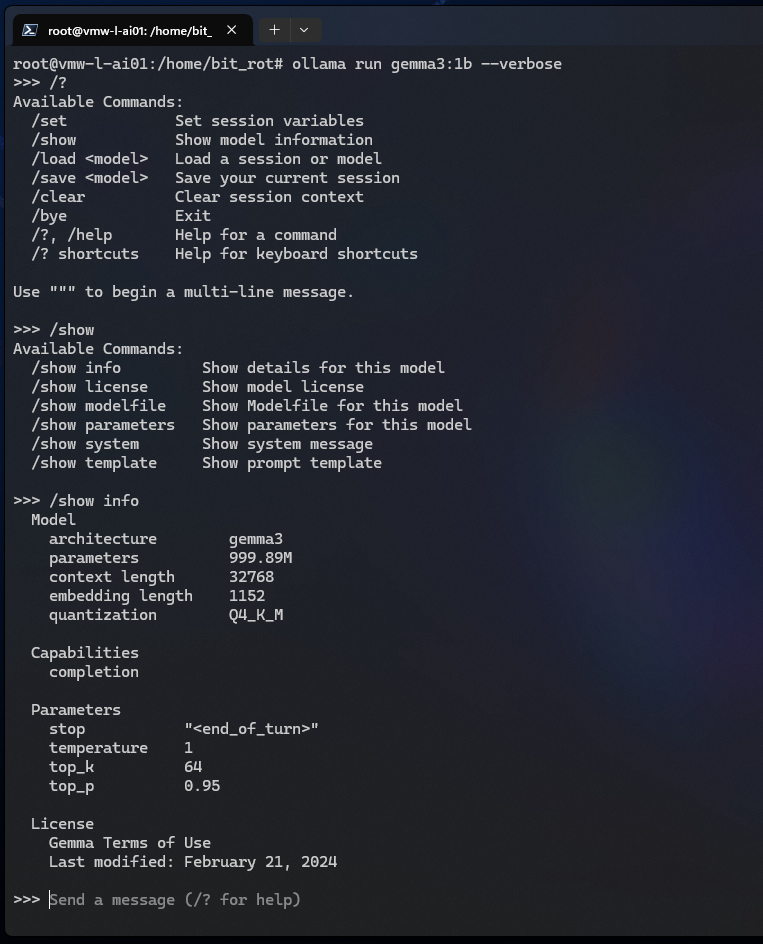
The /show command is useful for seeing various information about the model itself:
>>> /show >>> /show info
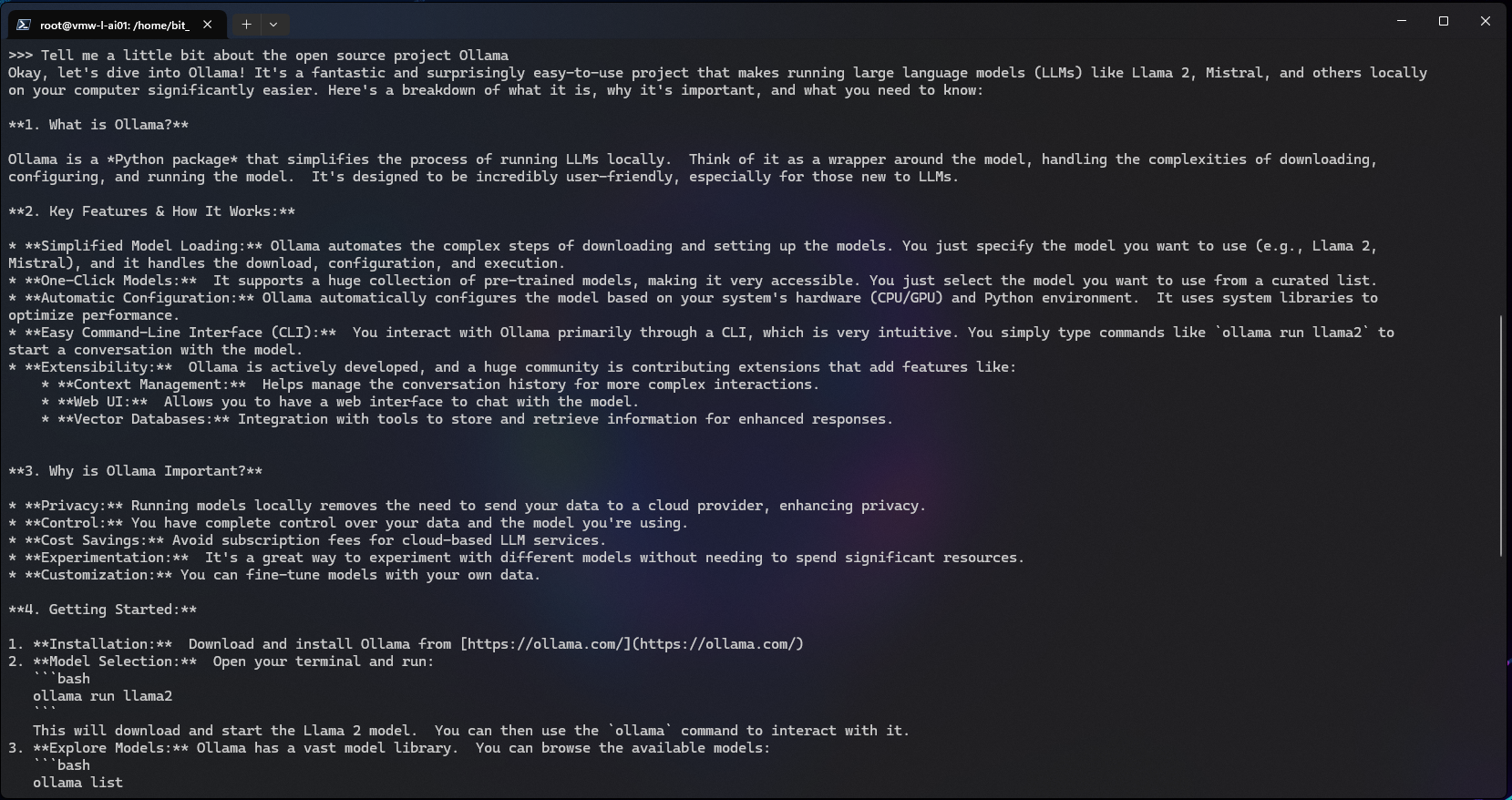
Let’s try asking it something:
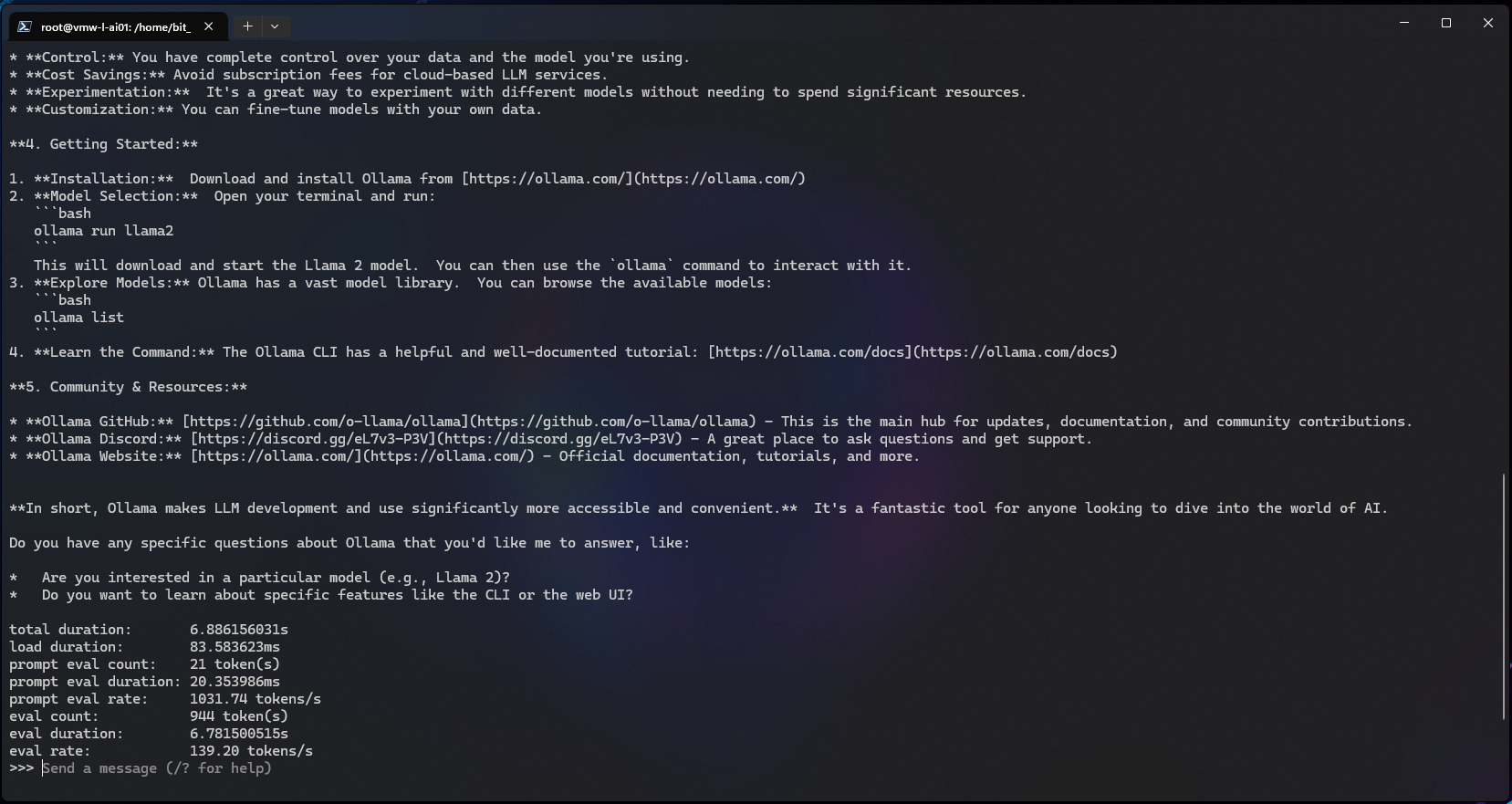
To exit the running session:
>>> /bye
Additional Notes:
-
Allowing External Network Access – By default, Ollama is only accessible from the local machine (127.0.0.1). To access Ollama from a remote host, this setting needs to be adjusted to allow connections on all interfaces (0.0.0.0). Be aware that opening network access introduces a security risk, by default there is no authentication, allowing anyone with network access to manage the Ollama instance. Restrict access using network ACLs wherever possible and never expose Ollama directly to the internet.
-
To expose the Ollama instance via local IP, edit the Ollama service:
# systemctl edit ollama.service
-
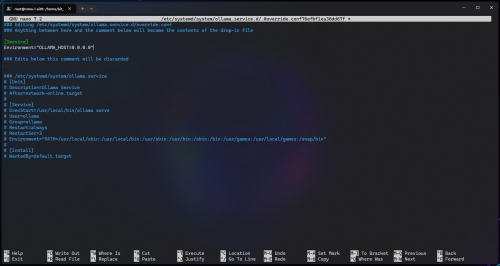
Add the following configuration, modifying the value from “127.0.0.1” (loopback) to “0.0.0.0” (all interfaces):
[Service] Environment="OLLAMA_HOST=0.0.0.0"
-
Restart the Ollama service:
# systemctl restart ollama
-
Verify the service is now listening on all interfaces:
# ss -antp Default configuration listening on 127.0.0.1: LISTEN 0 4096 127.0.0.1:11434 0.0.0.0:* users:(("ollama",pid=2194,fd=3)) Updated configuration listening on 0.0.0.0: LISTEN 0 4096 *:11434 *:* users:(("ollama",pid=2101,fd=3)) -
Using a remote host, you should also be able to browse to the Ollama host using the local IP:
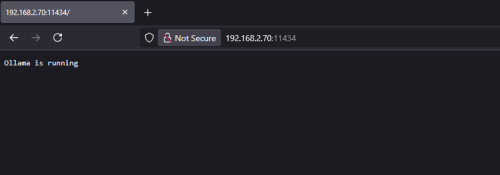
-
To expose the Ollama instance via local IP, edit the Ollama service:
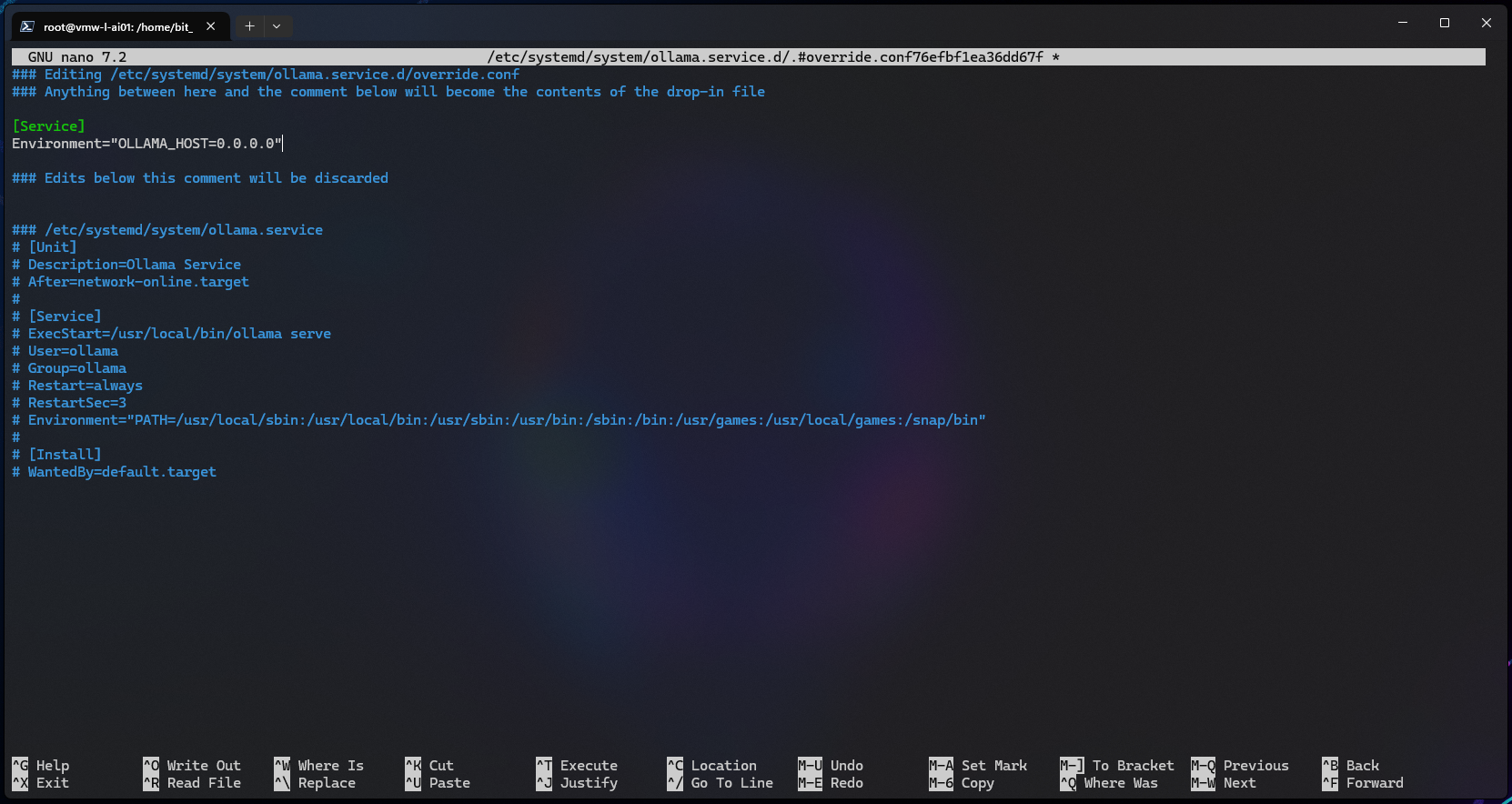
Choosing Models
When it comes to choosing models to run with Ollama, I’d recommend starting with the following repositories:
https://ollama.com/search
https://huggingface.co (GGUF Models)
Based on my experience, the Ollama team is super proactive and consistently releases regularly updated and stable versions of the most popular models. This is a great starting point and should meet the LLM needs of most users.
To download a model from Ollama’s repository, navigate to the “Models” section at the top, select a model and size, and the corresponding ollama run command will be displayed on the right:
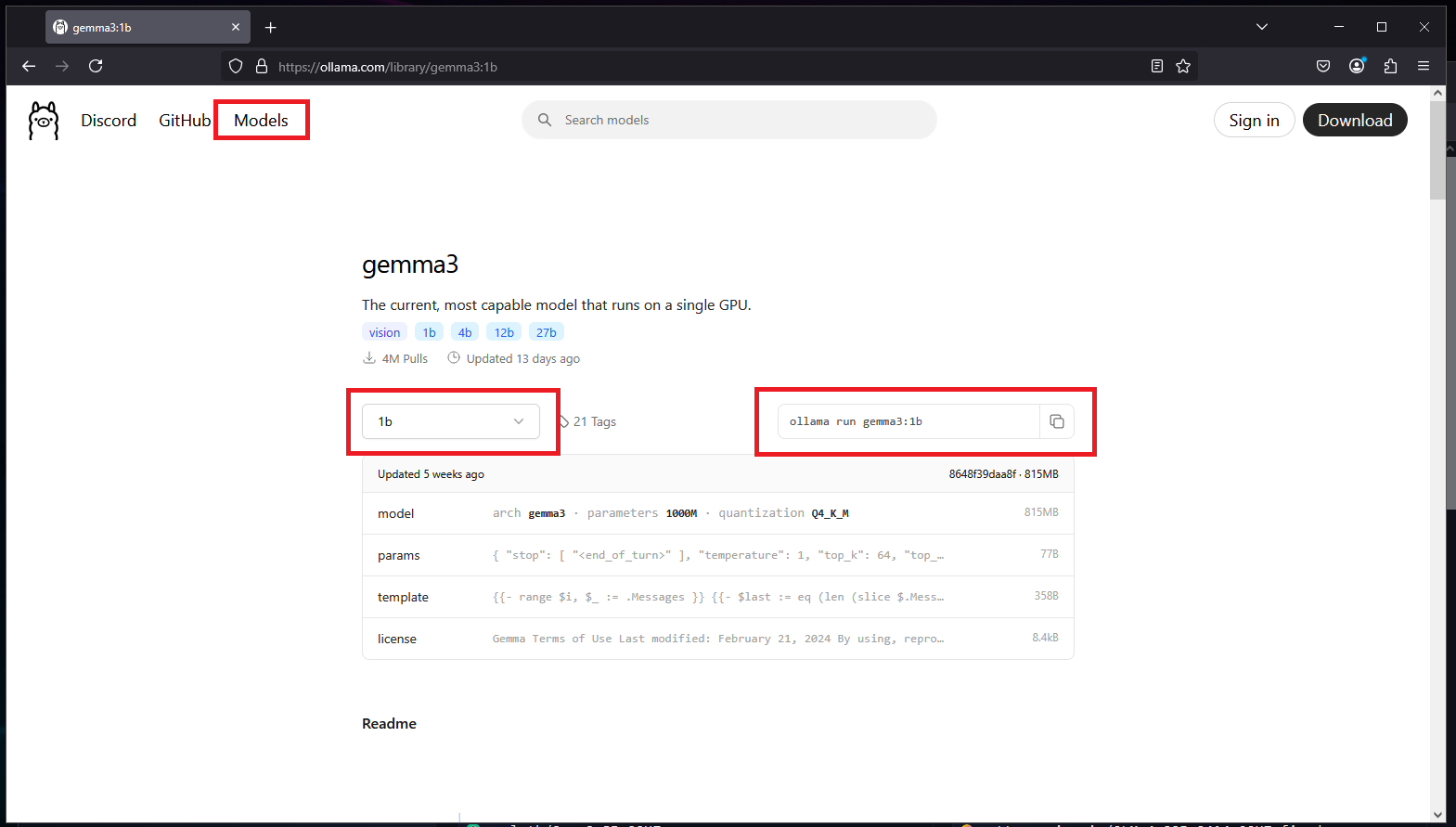
For those slightly more adventurous, Hugging Face is community based and is a little more like the cutting edge wild wild west of AI, maybe not as polished for specifically running with Ollama, but lot’s of very interesting projects.
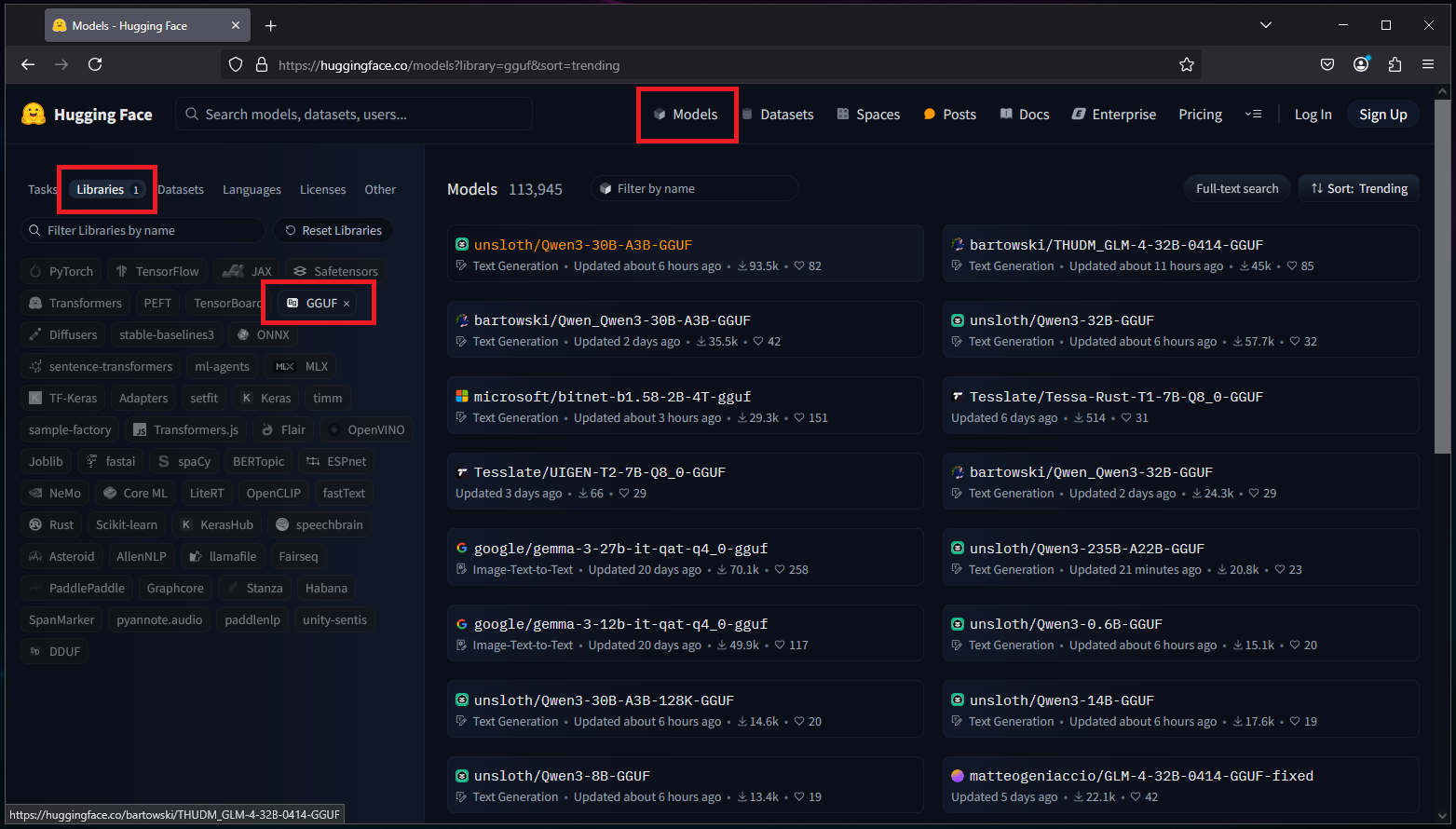
To download a model from Hugging Face, select “Models” on the top then “Libraries” and filter to “GGUF”:
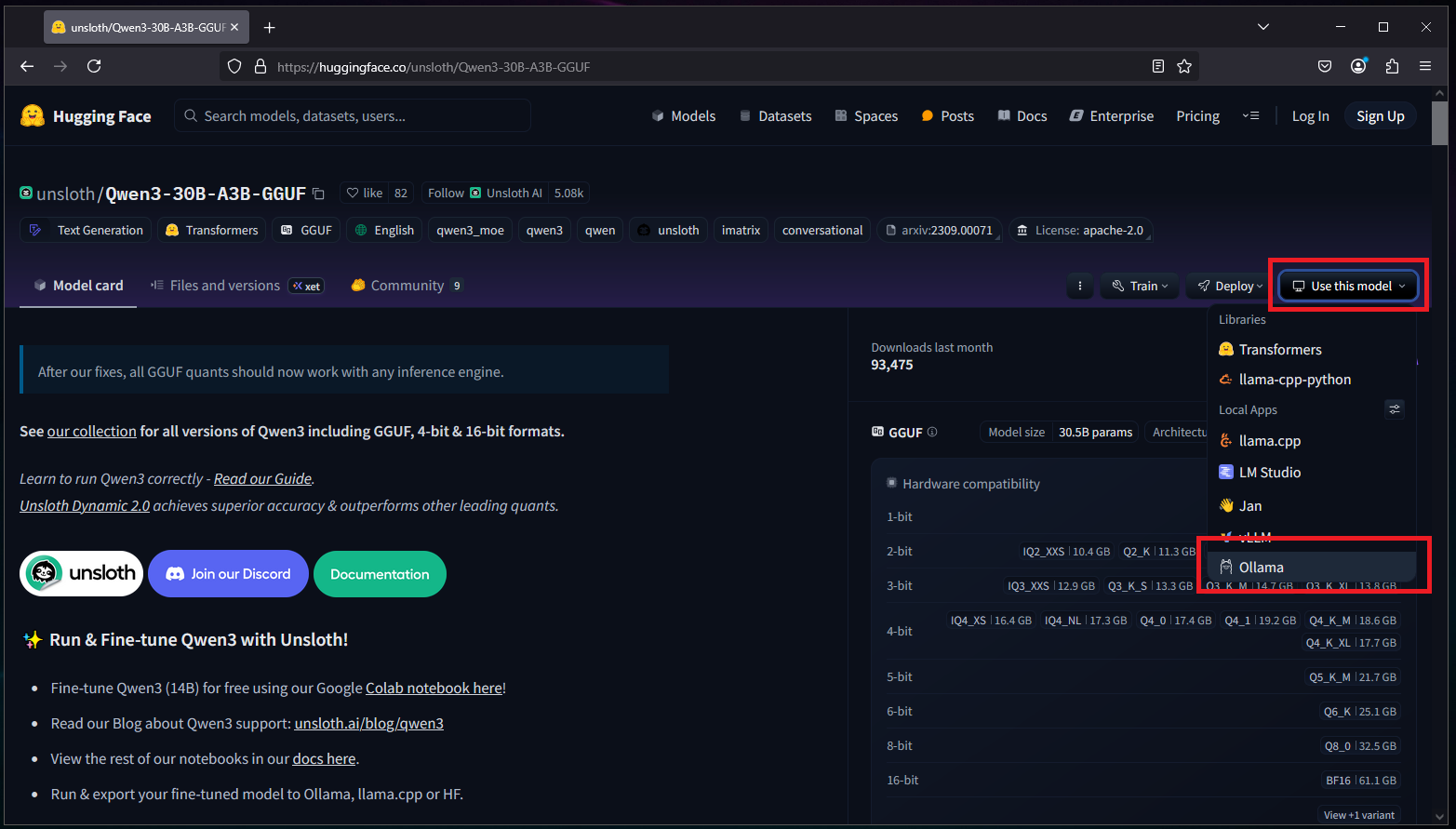
After selecting a model, towards the right there should be a “Use this model” button with an Ollama option:
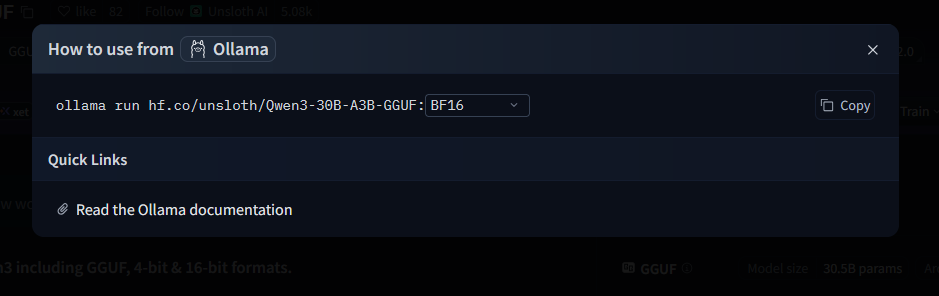
The Ollama run command will then be displayed:
Now as far as downloading correctly sized models for your hardware, that becomes considerably more complicated. Trying to keep things as simple as possible, most models are described in size by the amount of parameters in billions – 1b, 7b, 14b, etc. The more parameters, the more memory will be needed. The end goal is to be able to fit the model & intermediate calculations observed during inference into memory to ensure optimal performance.
As a general rule of thumb, I tend to take the size of the LLM on disk, multiply it by 1.5 and if it’s under the physical memory limit, I’ll give it a run but then verify the resource usage manually using the tools mentioned in the “Host Monitoring” section (see below).
As an example, when selecting models to run on a GPU with 16GB of VRAM, here’s how I would begin. Let’s compare Gemma 3 12b versus Gemma 3 27b on Ollama’s repository.
gemma3 12b:
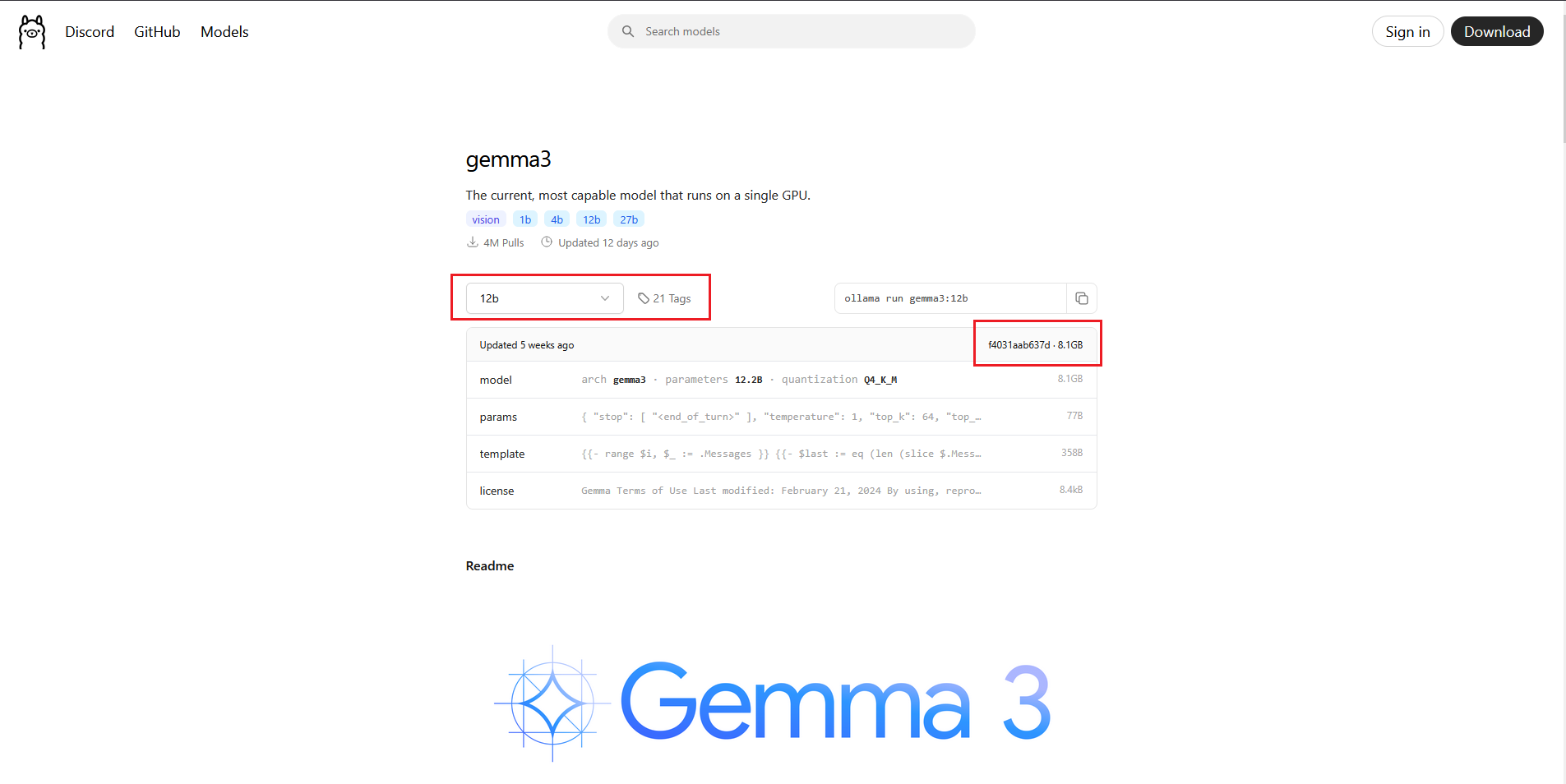
gemma3 27b:
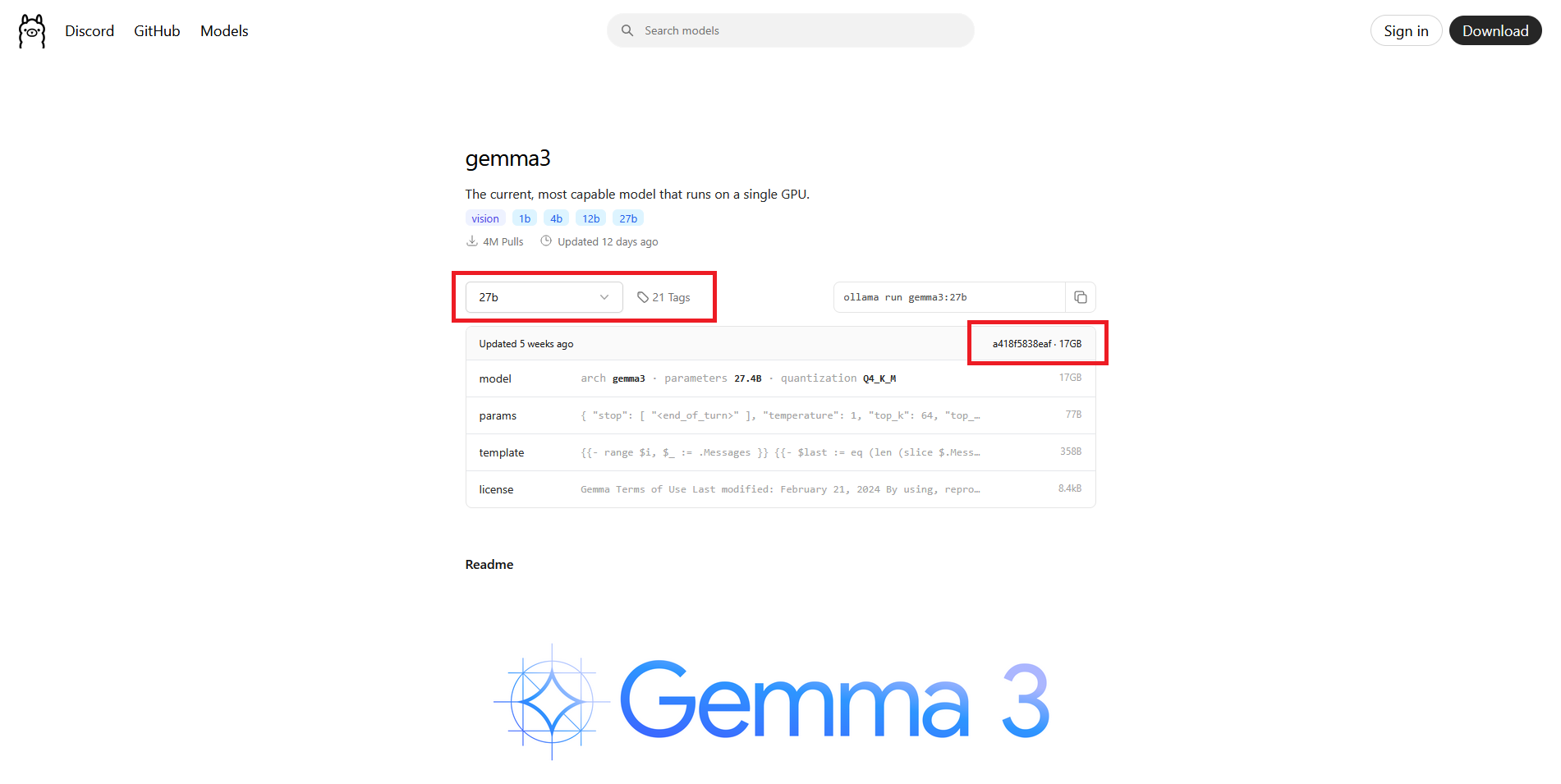
Based on the information above and using the size on disk multiplied by 1.5 formula, it appears that Gemma 3.0 12b (8.1GB) would offer good performance on a GPU with 16GB VRAM, while Gemma 3.0 27b (17GB) likely would not. Again, this is a general guideline but proves to be pretty effective when combined with additional resource monitoring.
Here are some models I really like and have been using regularly:
- gemma3
- phi4
- deepseek-r1
Open WebUI
For the “frontend” or chat portion of this setup, I will be using Open WebUI, which is also open-source and free:
https://openwebui.com/
Open WebUI provides a sleek frontend with robust LLM connectivity and a variety of additional features, greatly reducing the need for additional projects or custom solutions.
Here are just a few of the awesome features available:
- Local RAG Integration
- Web Search for RAG/Web Browsing
- Extensible using python based tools/functions in addition to pipelines for advanced workflows
- Arena – for comparing the response of models to a specific query
- Easily create, download, and manage Ollama models via the Web UI
- MCP Support
- OpenAI API Integration
Installing Docker
The easiest way to run Open WebUI is using Docker, so let’s check to see if Docker is installed:
# docker --version Docker version 26.1.3, build 26.1.3-0ubuntu1~24.04.1 # docker info Client: Version: 26.1.3 Context: default Debug Mode: false ...
If docker is not installed, you can locate the available Docker packages using apt-cache:
# apt update && apt-cache search docker docker.io - Linux container runtime
To install Docker:
# apt install docker.io
Enable Docker to start with the host:
# systemctl enable docker
Nvidia Container Support
To enable Nvidia support for Docker containers, there are a few additional packages that might need to be installed and configured:
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
Otherwise, you will likely receive the following error when attempting to start the Open WebUI container with GPU support:
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]]
Install the Nvidia Docker packages:
# apt install nvidia-container-toolkit
Configure the container runtime:
# nvidia-ctk runtime configure --runtime=docker
Restart the Docker service:
# systemctl restart docker
Installing Open WebUI
The Open WebUI documentation can be found here:
https://docs.openwebui.com/getting-started/quick-start
https://github.com/open-webui/open-webui
Pulling down the Open WebUI Docker image:
# docker pull ghcr.io/open-webui/open-webui:main
Before starting the Open WebUI container, be aware there’s a few issues that may come up if running Ollama on the same host. Open WebUI has some great troubleshooting tips that can be found here:
https://docs.openwebui.com/troubleshooting/connection-error/
Open WebUI – Docker Run Option 1
The typically recommended approach for running Ollama and Open WebUI on the same host is to leverage –add-host=host.docker.internal:host-gateway:
# docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
This should allow the Open WebUI container to reach the Ollama service running on the host by using http://host.docker.internal:11434.
With Ollama listening on the default loopback IP (127.0.0.1), the connection fails:
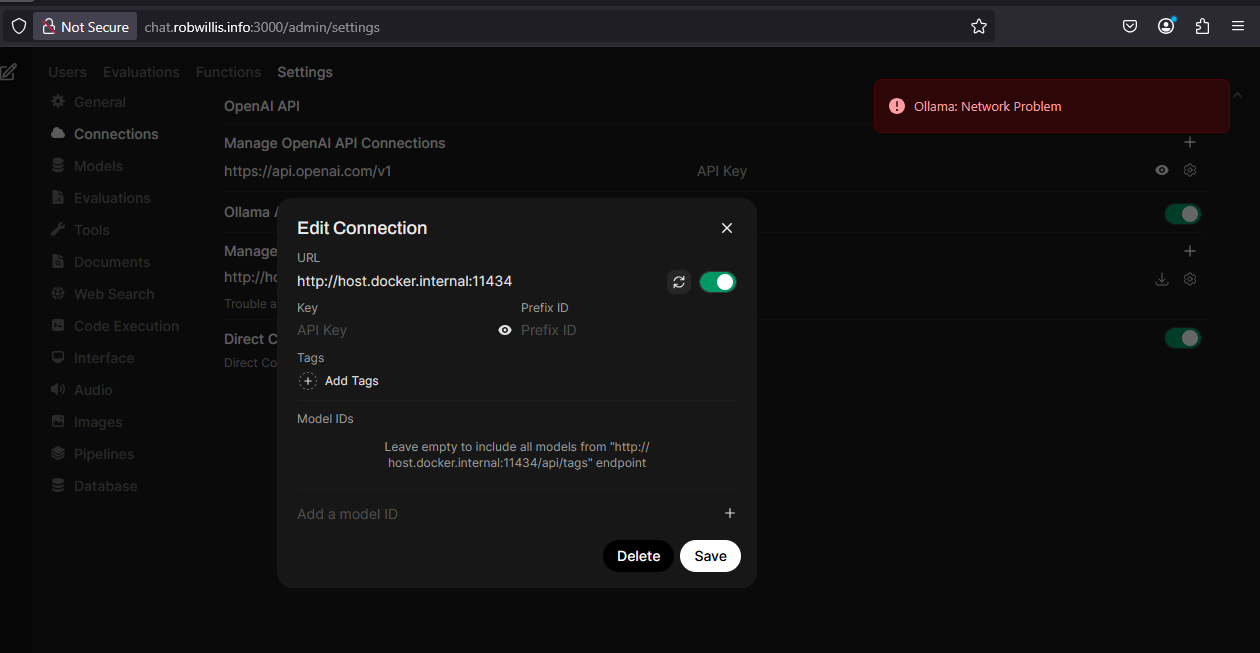
To resolve this, reconfigure Ollama to listen on all interfaces (0.0.0.0):
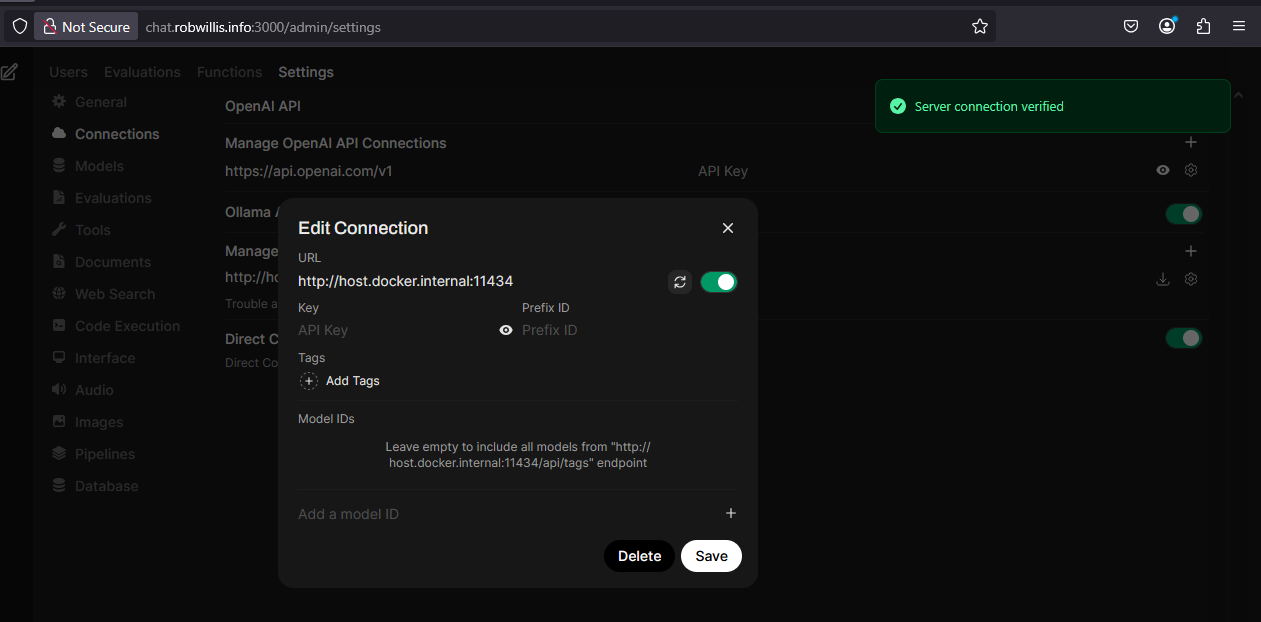
Check out the “Additional Notes” section under “Managing Ollama” (see above) for more information on how to make this adjustment.
Open WebUI – Docker Run Option 2
Another option is to use –network host in combination with the OLLAMA_BASE_URL environmental variable:
# docker run -d -p 80:8080 --network host --restart always --gpus all -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
Using “–network host” is the more blunt and less preferred option since it bypasses the Docker network stack, losing the benefits of isolation, and exposes the Open WebUI container directly but also allows the Ollama service to remain internal on the default 127.0.0.1. Another gotcha that comes up when using “–network host” is that the setting will also override the port mapping settings (-p 3000:8080), resulting in Open WebUI listening on IP:8080.
Both commands have their pro’s and con’s, but with this project being a single physical server I opted to use “–network host” since I trust the container to access the host and preferred not manage the overhead the comes with exposing Ollama while not having a need to.
My slightly adjusted version:
# docker run -d --network host --restart always --gpus all -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main

Additional arguments explained:
- -d – Detached mode executes the command and immediately returns you to the terminal prompt. Without detached mode, the terminal remains connected to the container, keeping it running until you manually stop it or close the terminal session.
- –restart always – Make sure the container always restarts with the host.
- –gpus all – Enable GPU support, important if you plan on using Open WebUI’s built-in engine for RAG.
- -e – Setup an environmental variable to update the connection to the Ollama server.
- -v – Establish a local storage volume for persistent storage.
Now to browse over to the server via “http://IP:8080” or if you want to get fancy, create a local DNS A record so you can hit it by something like “http://chat.robwillis.info:8080” instead:
Additional Notes:
-
Auto Restart With Host
-
To ensure the Open WebUI container restarts with the host, make sure the Docker service is enabled:
# systemctl is-enabled docker disabled # systemctl enable docker Created symlink /etc/systemd/system/multi-user.target.wants/docker.service → /usr/lib/systemd/system/docker.service.
-
And then make sure to use the –restart always parameter with the Docker run command:
# docker run -d -p 3000:8080 --gpus all -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
-
To ensure the Open WebUI container restarts with the host, make sure the Docker service is enabled:
- DNS Trickery – The local DNS A record was accomplished using an unbound DNS host override via local firewall.
Auto Updating Open WebUI With Watchtower
All of the information covered below can be found in the Open WebUI documentation:
https://docs.openwebui.com/getting-started/updating/
You can manually update the Open WebUI container using the following commands:
# docker stop open-webui # docker rm open-webui # docker pull ghcr.io/open-webui/open-webui:main # docker run -d --network host --restart always --gpus all -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
Don’t be afraid of the docker rm command, it only removes the container and not the associated volume, no data will be lost.
This step is not needed, but if you did want to wipe all data, the Open WebUI volume can be deleted using the following command:
# docker volume rm open-webui
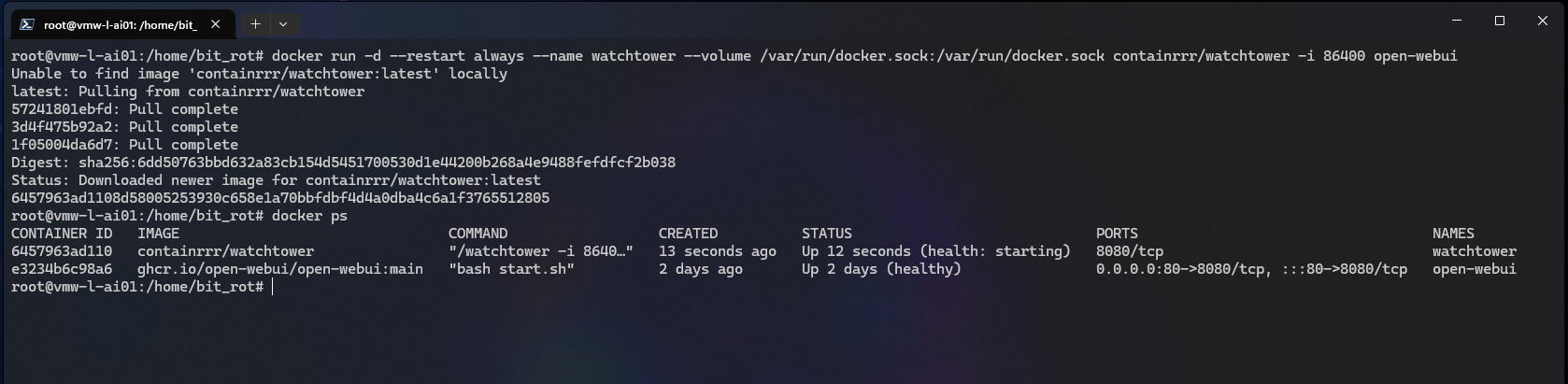
These steps are pretty simple, but Open WebUI is updated pretty regularly, so to streamline the process you can use Watchtower, which will run as an additional container.
My slightly modified version, adding restart always and changing it to run every 24 hrs:
# docker run -d --restart always --name watchtower --volume /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower -i 86400 open-webui
Basic Usage
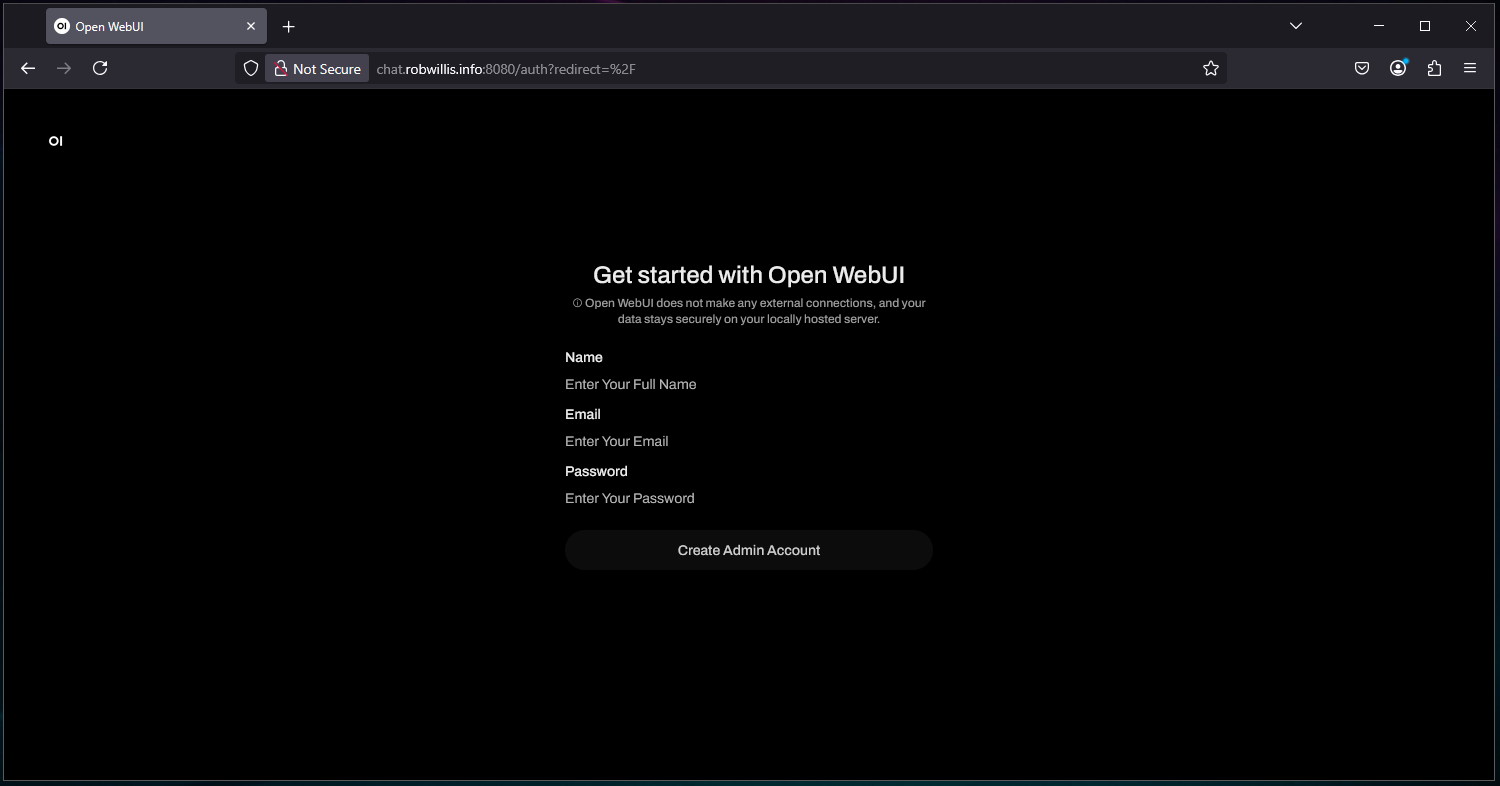
Now that Open WebUI is up and running, click on the “Get started” button to….get started. 🙂
The first user to access the instance will be prompted to create the Admin account:
And we finally get to see the chat interface:
Asking a simple question to verify everything is working:
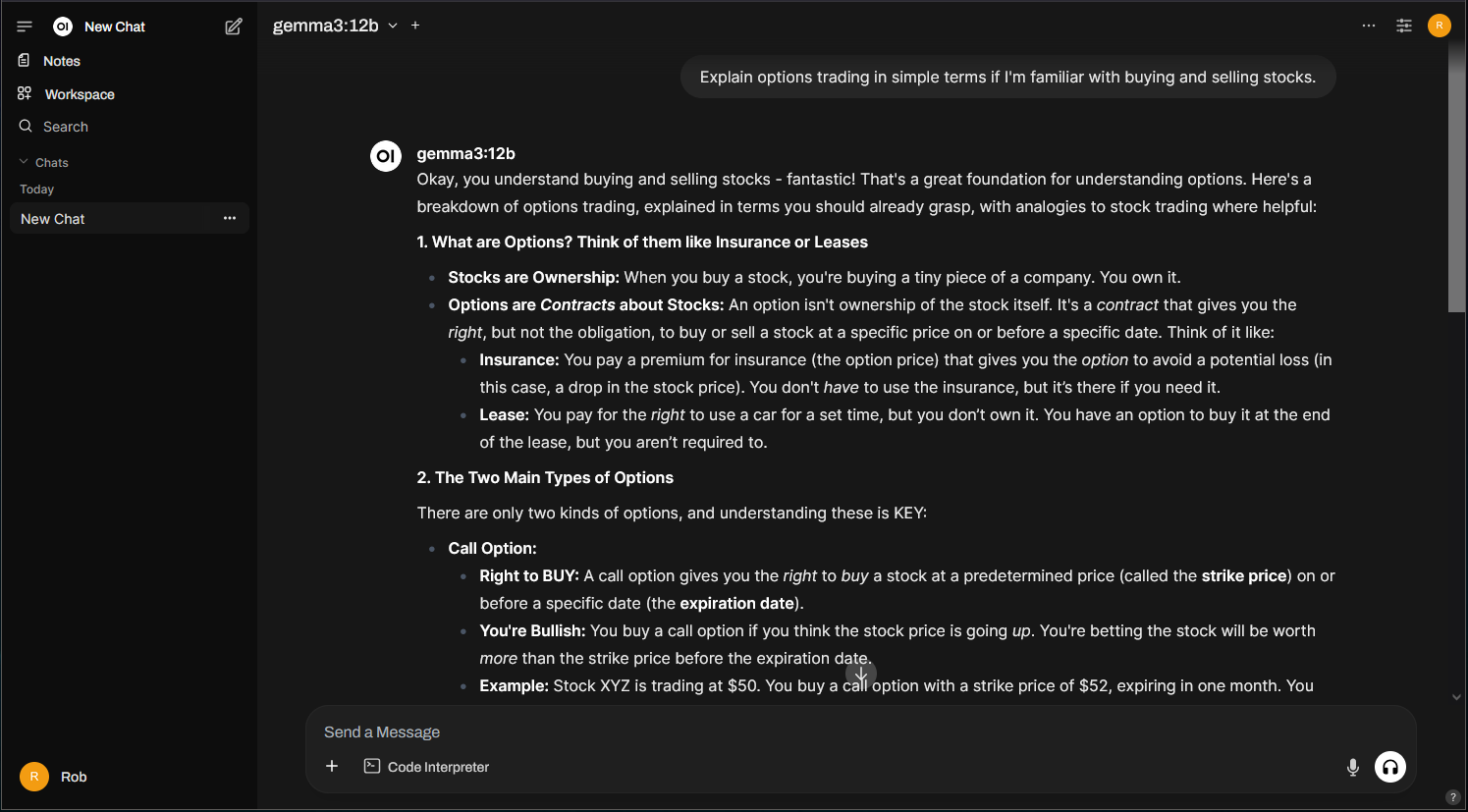
Let’s explore the interface in more detail.
On the left, you’ll find your current and past chats, along with advanced options like Workspaces and Notes.
To the right, you can select the model to be used, this is also where you can set the default model. It’s worth noting that you can switch models while you’re in the middle of a conversation or add (“+”) additional models for an “arena” style response showdown – pretty neat, right?
Finally, on the far right are the “Chat Controls”, a collection of adjustable settings that influence the current session. While there are many options, key settings like the system prompt, temperature, and context length are readily accessible here. This is a great way to experiment with these settings and observe how they affect responses:
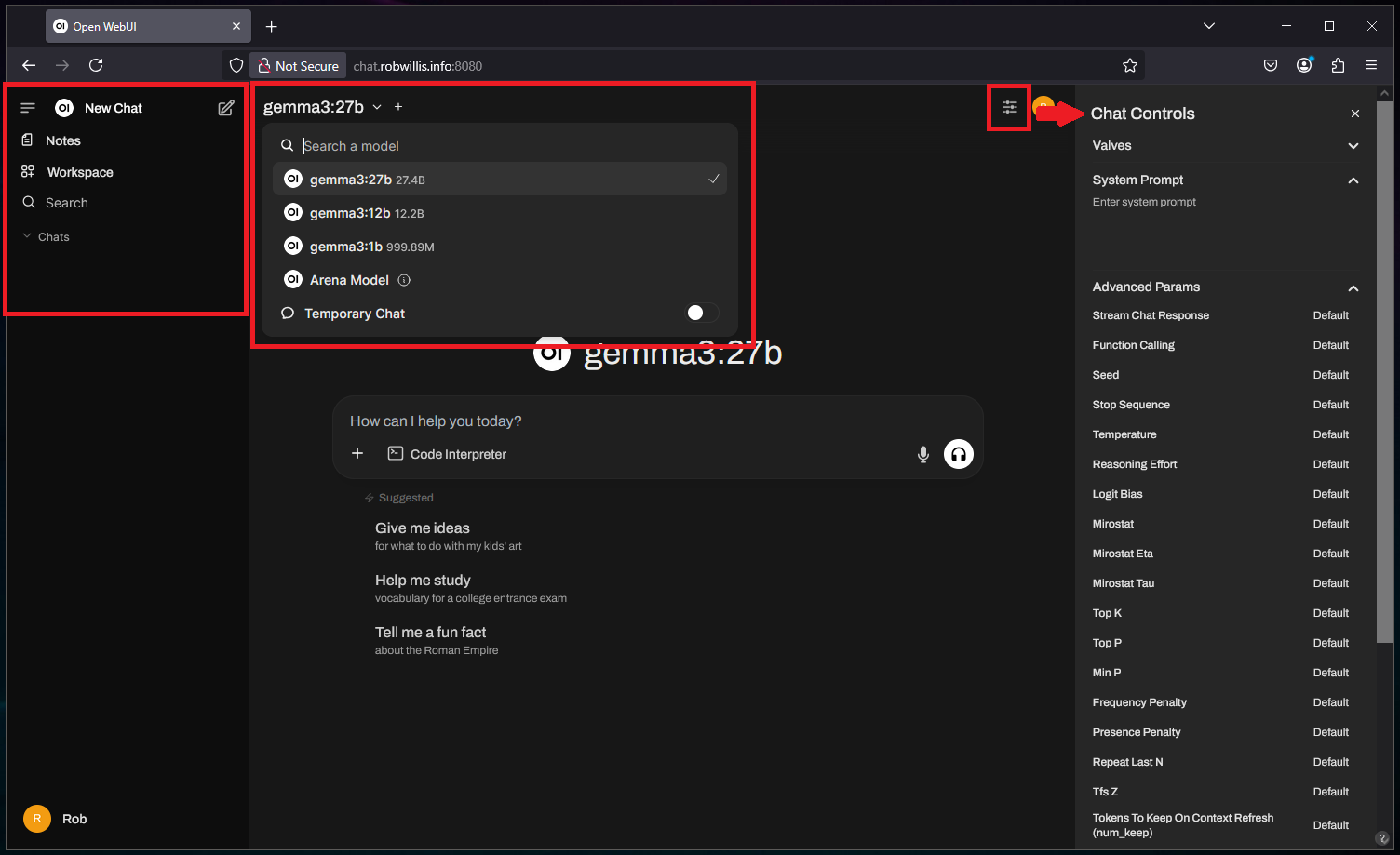
Clicking on the user avatar icons will display the main Open WebUI menu, which includes both the “Settings” and “Admin Panel”:
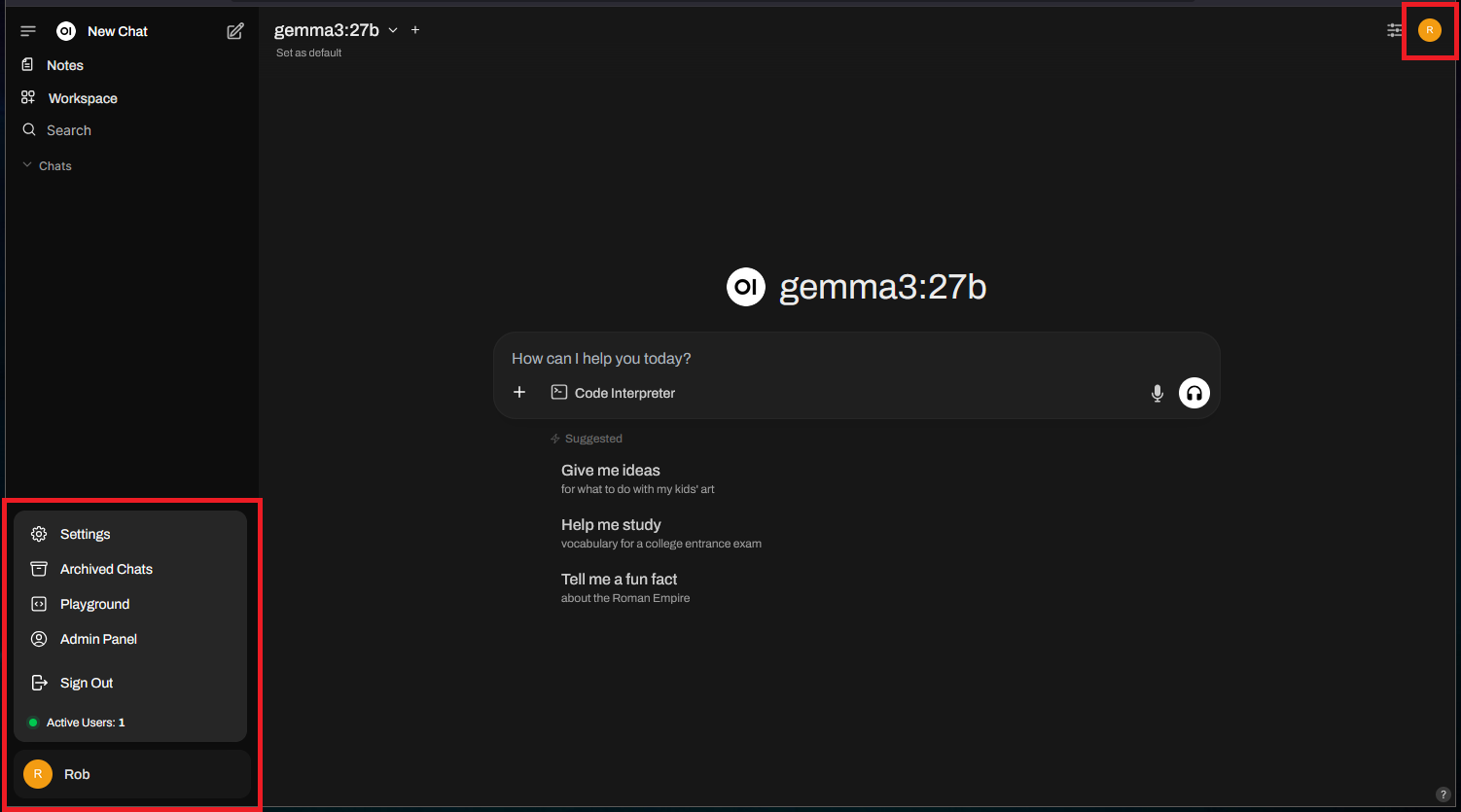
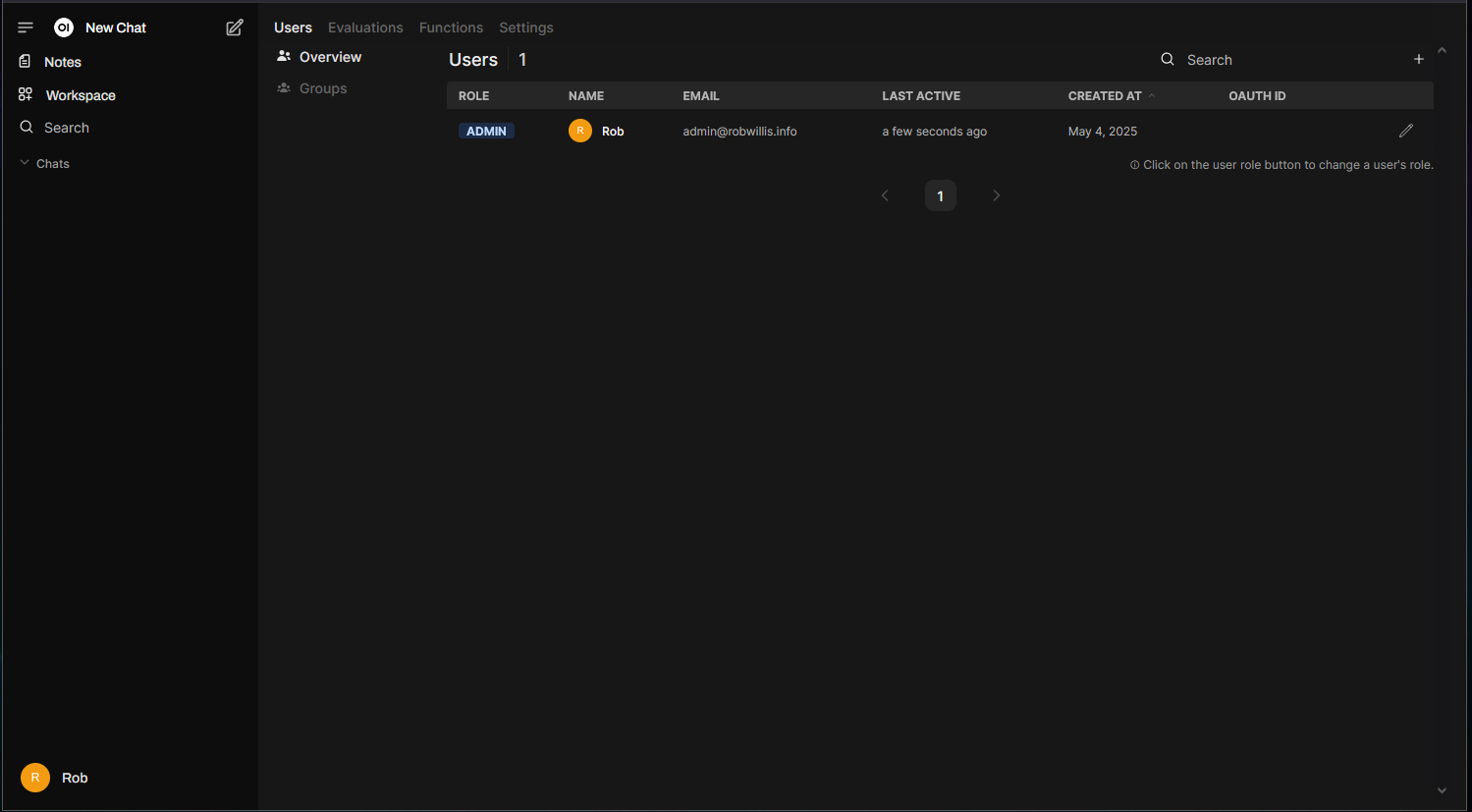
Within the “Admin Panel” > “Users”, you’ll find the Open WebUI user management:
In the “Admin Panel” > “Settings” > “General” section, you can enable “New Sign Ups” along with a bunch of other advanced options:
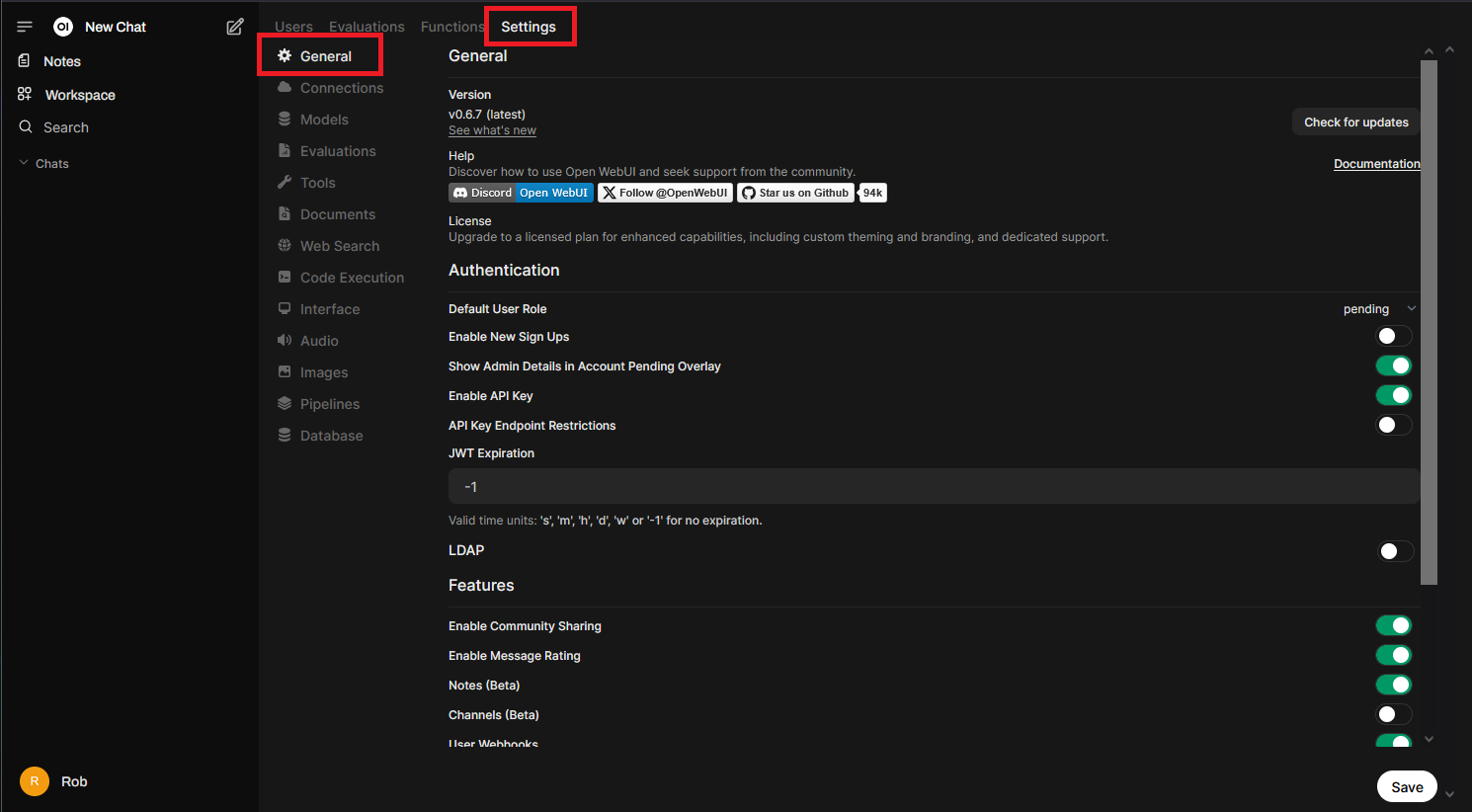
This is only a quick overview, but it should provide enough to get started. As you can see, there is a lot to Open WebUI, I highly recommend exploring the menus to get more familiar with all of the options available.
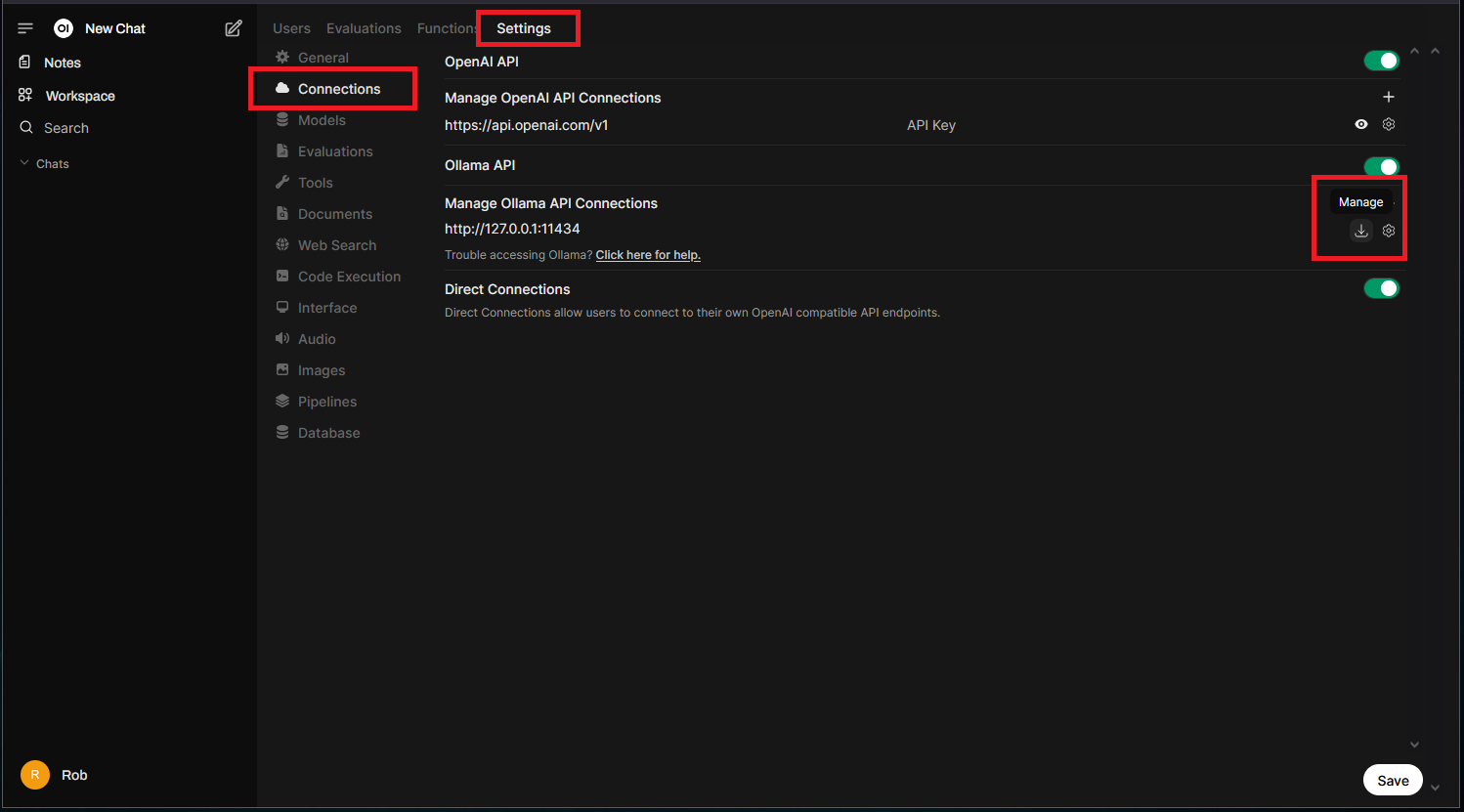
Downloading & Managing Models
To get started with downloading and managing Ollama models in the Open WebUI interface, go to the “Admin Panel” > “Settings” > “Connections” section and click the “Manage” button under “Ollama API”:
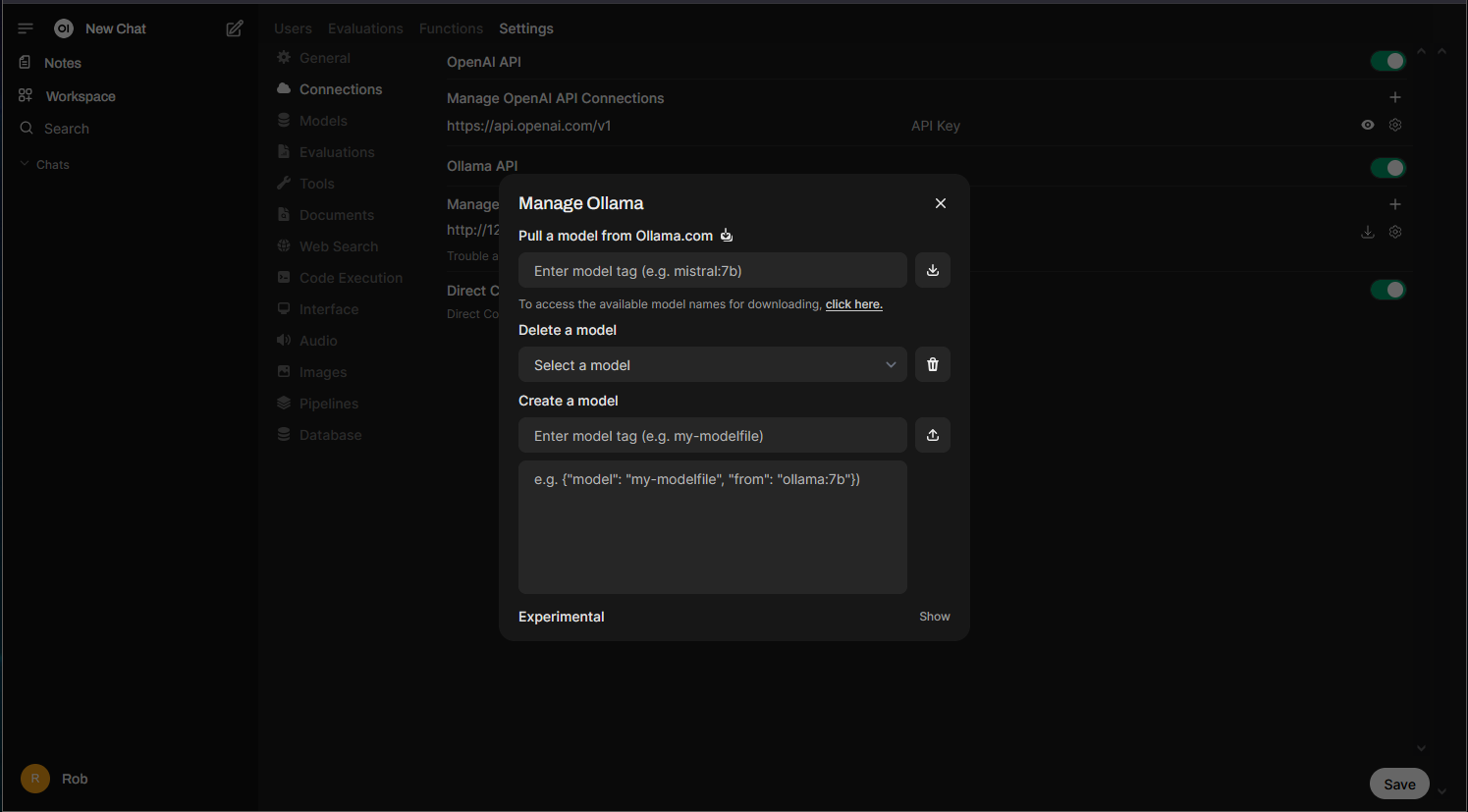
Here, you can download models from the Ollama.com library, using the model tag found with the ollama run commands earlier. You can also delete and create models:
The “Models” section (below “Connections”) allows you to enable/disable models and adjust their settings:
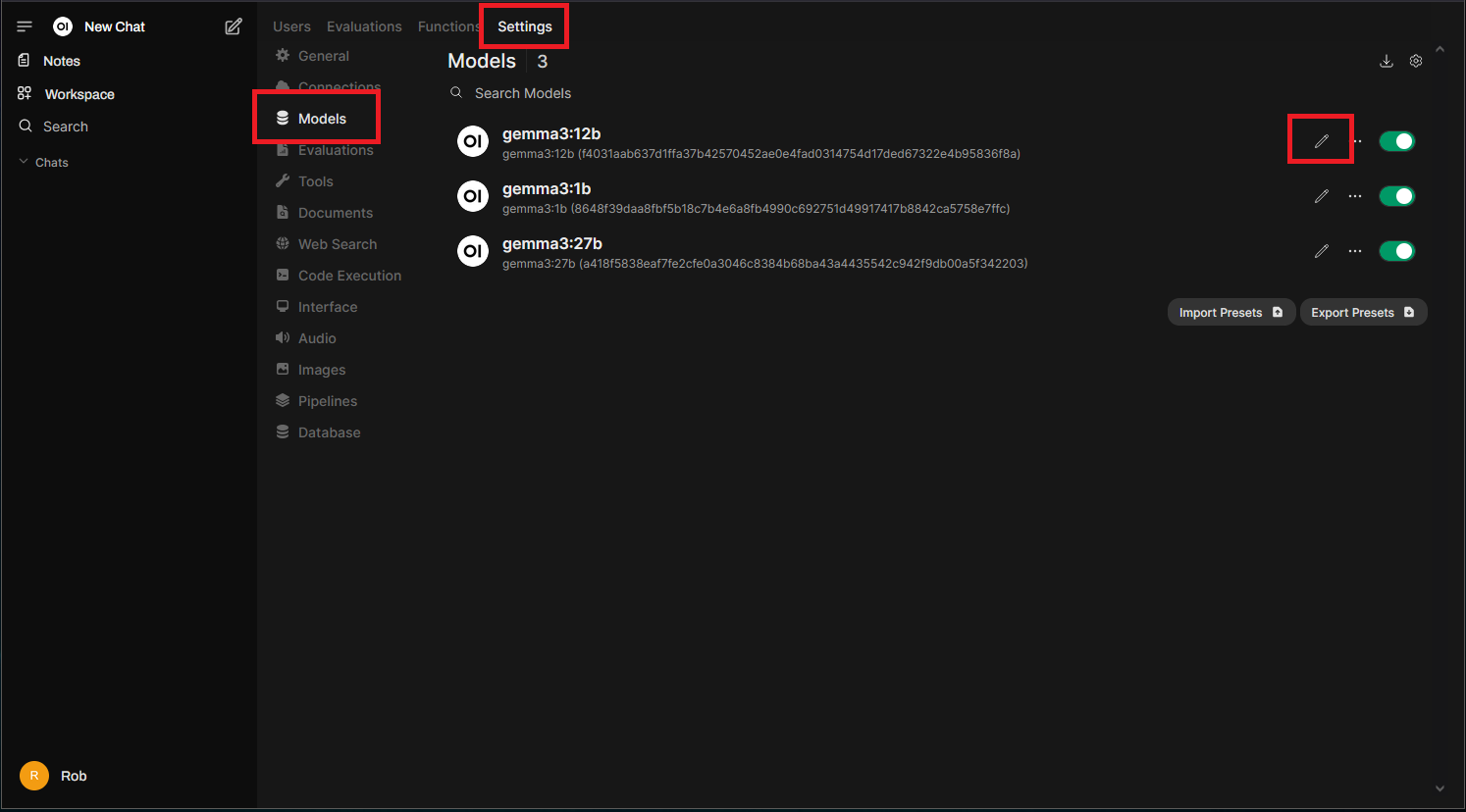
Clicking the pencil icon to edit a model’s settings will reveal options similar to the “Chat Controls” seen earlier in the chat session. Unlike those controls, these settings are persistent. You’ll also find additional options for Knowledge, Tools, Filters, Actions, and more:
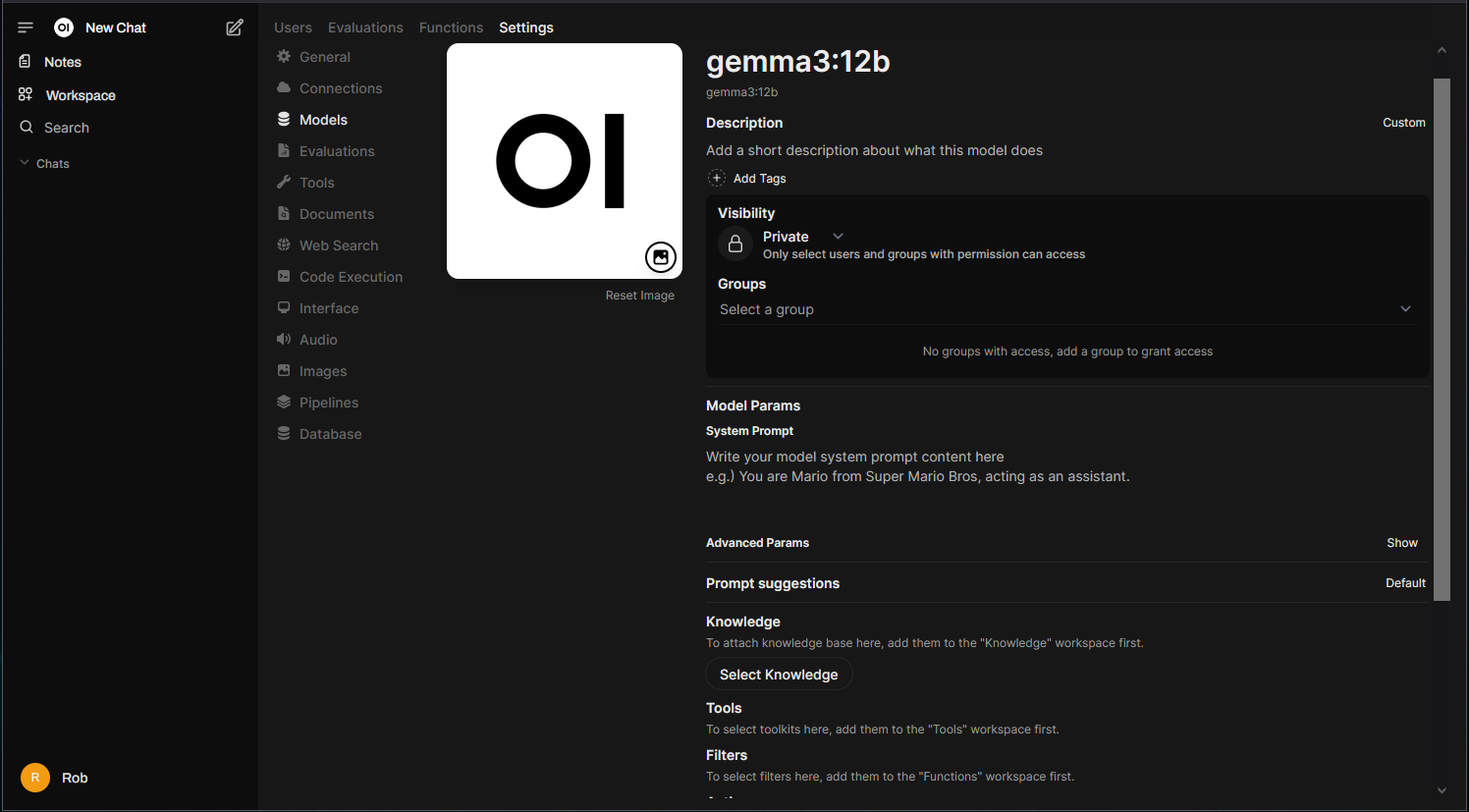
Documents & Knowledge (RAG)
Retrieval Augmented Generation (RAG) allows you to search and enhance your own documents, such as PDFs, using AI. Open WebUI simplifies this process, while also offering some advanced options for greater flexibility.
Emedding Model Engine
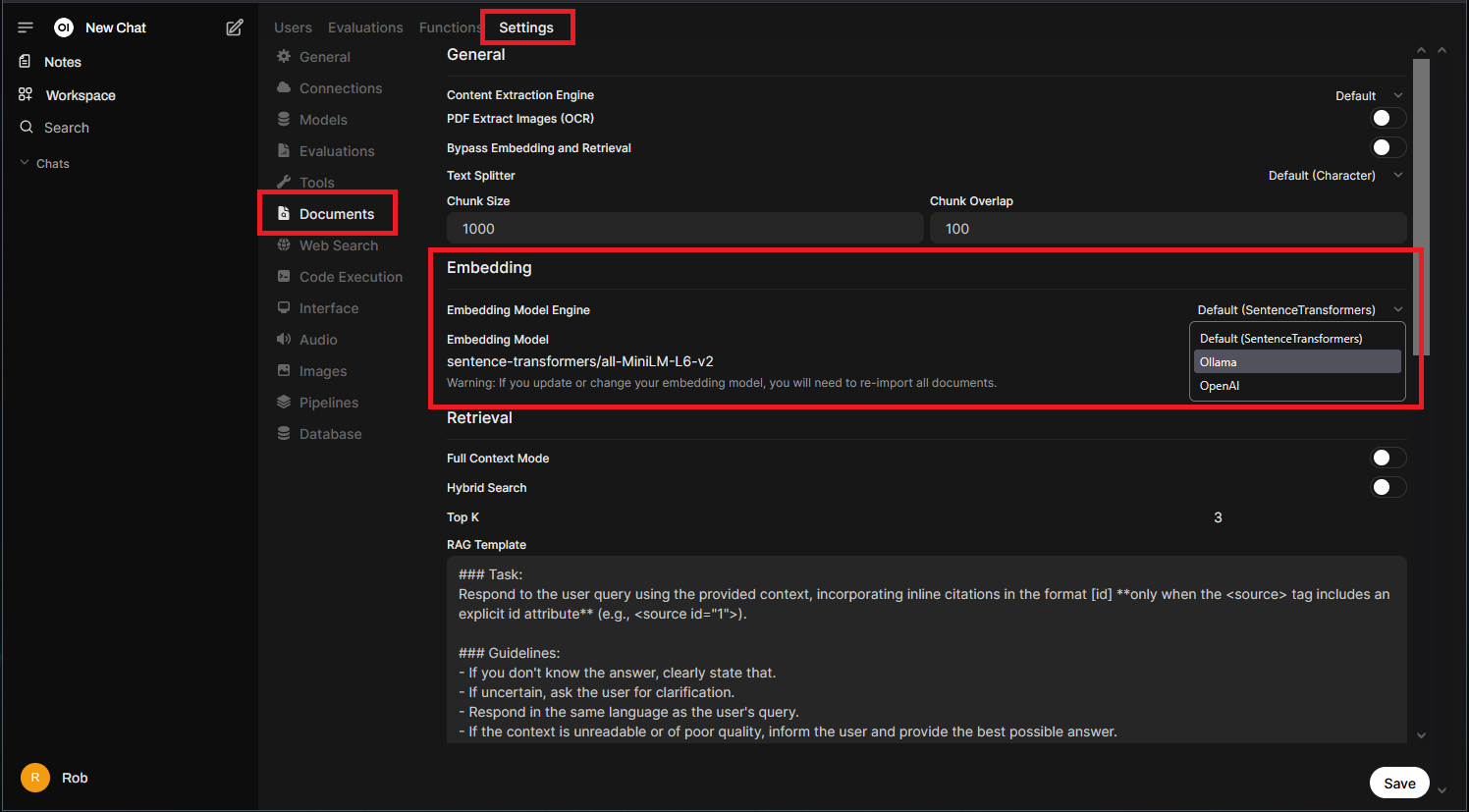
Under the “Admin Panel” > “Settings” is the “Documents” section, you can change the embedding model engine to use the default internal engine, or offload this load to a remote Ollama or OpenAI server. This choice is particularly important when considering GPU placement. If you’ll be using the Open WebUI RAG system, GPU support is recommended:
The Context Length Issue
When looking at the Open WebUI documentation, there is a specific note about adjusting the context length to 8192+ tokens when using Ollama:
https://docs.openwebui.com/features/rag
Ollama’s default 2048-token context length is optimized for faster response times and reduced memory usage, but can limit its ability to retain information in extended conversations.
This means the system might not use all retrieved data because it’s too large for the context window. To fix this, the context length should be increased to 8192 tokens or higher.
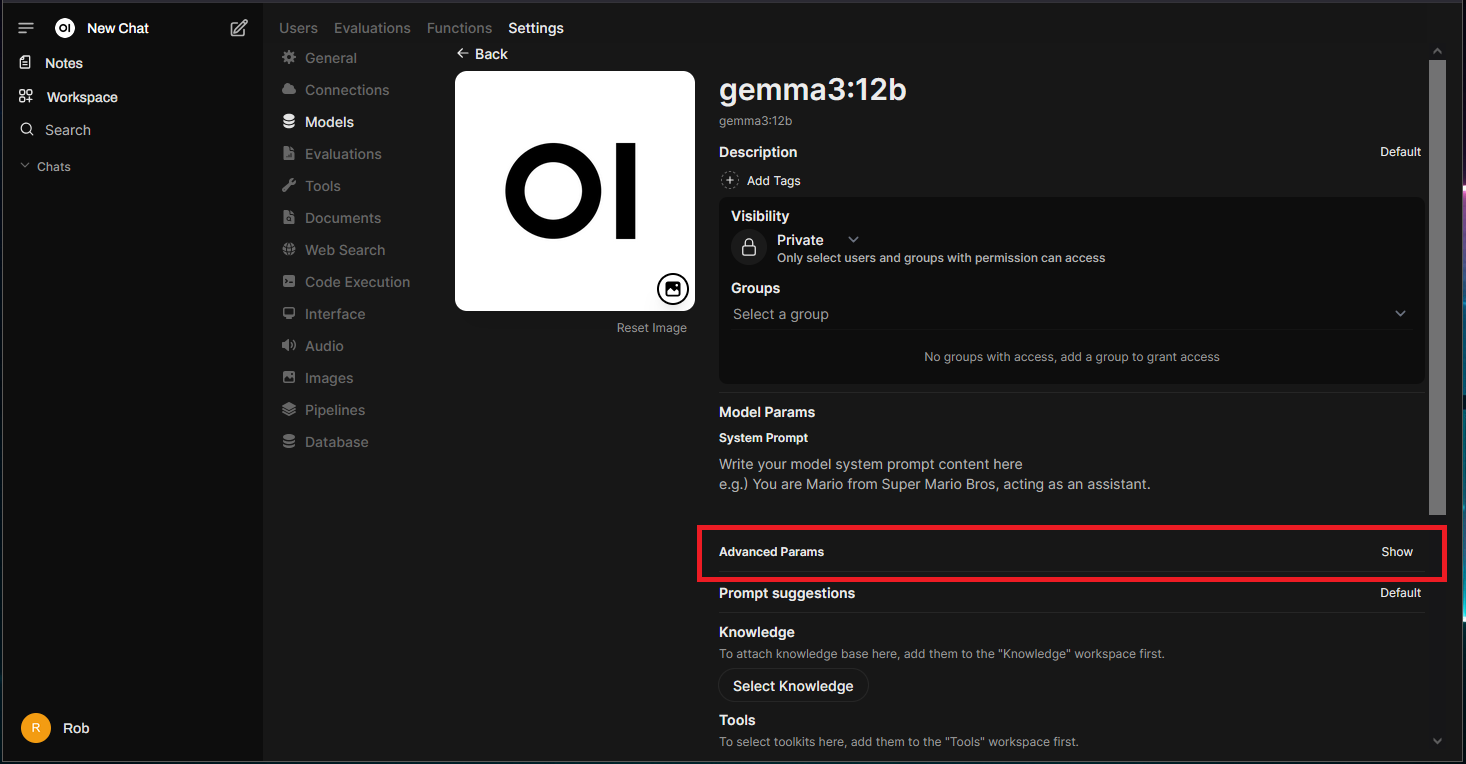
To adjust this setting go to “Admin Panel” > “Settings” > “Models”, select the pencil icon on the model that you will be using:
Click on “Show” under “Advanced Params”:
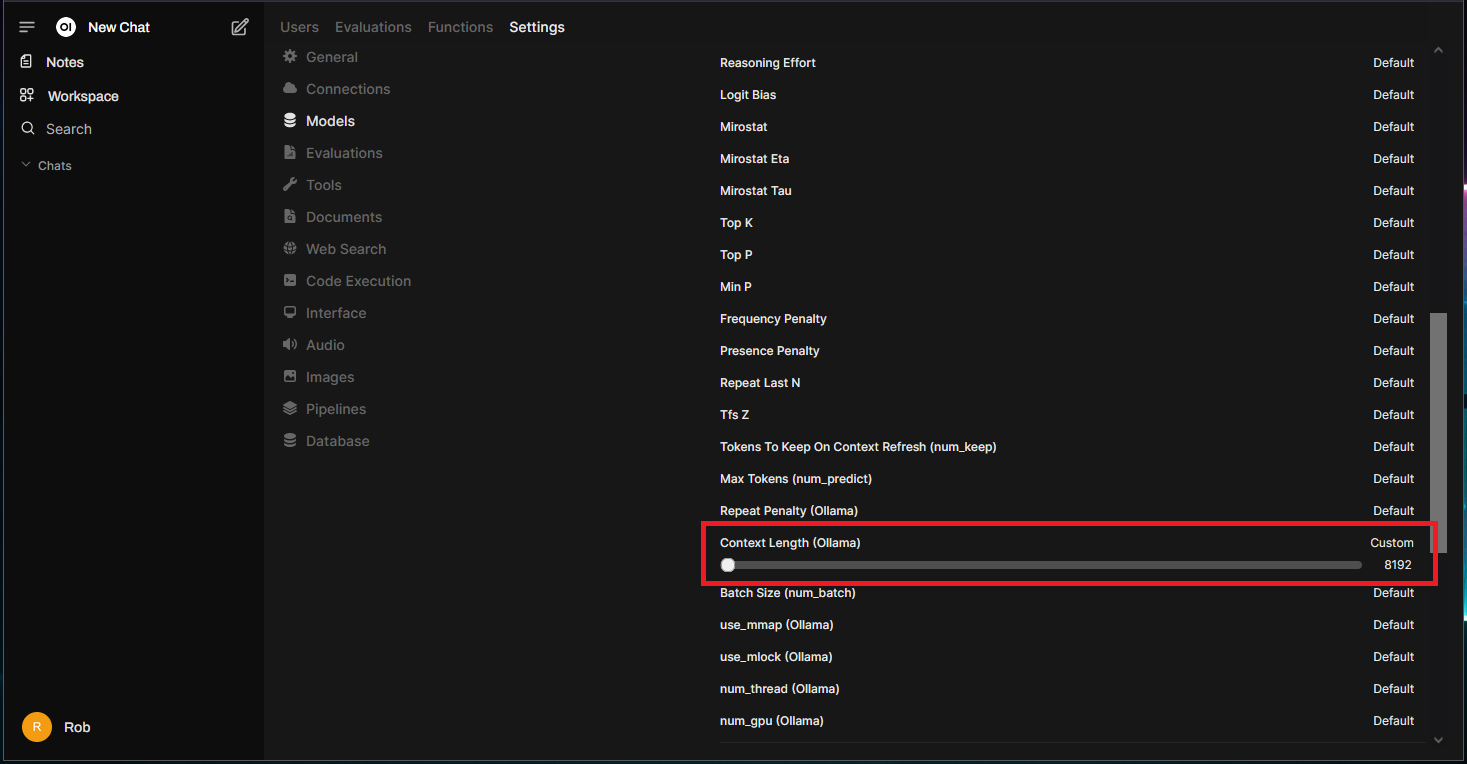
Locate the “Context Length (Ollama)” parameter and set it to 8192 as a starting point. Don’t be like me and use the slider that jumps around at like a million per pixel, you can just click the number and type it in:
If you are still running into issues where it seems like the RAG data is not being used and the context length has already been adjusted, try enabling “Full Context Mode” under the “Documents” section:
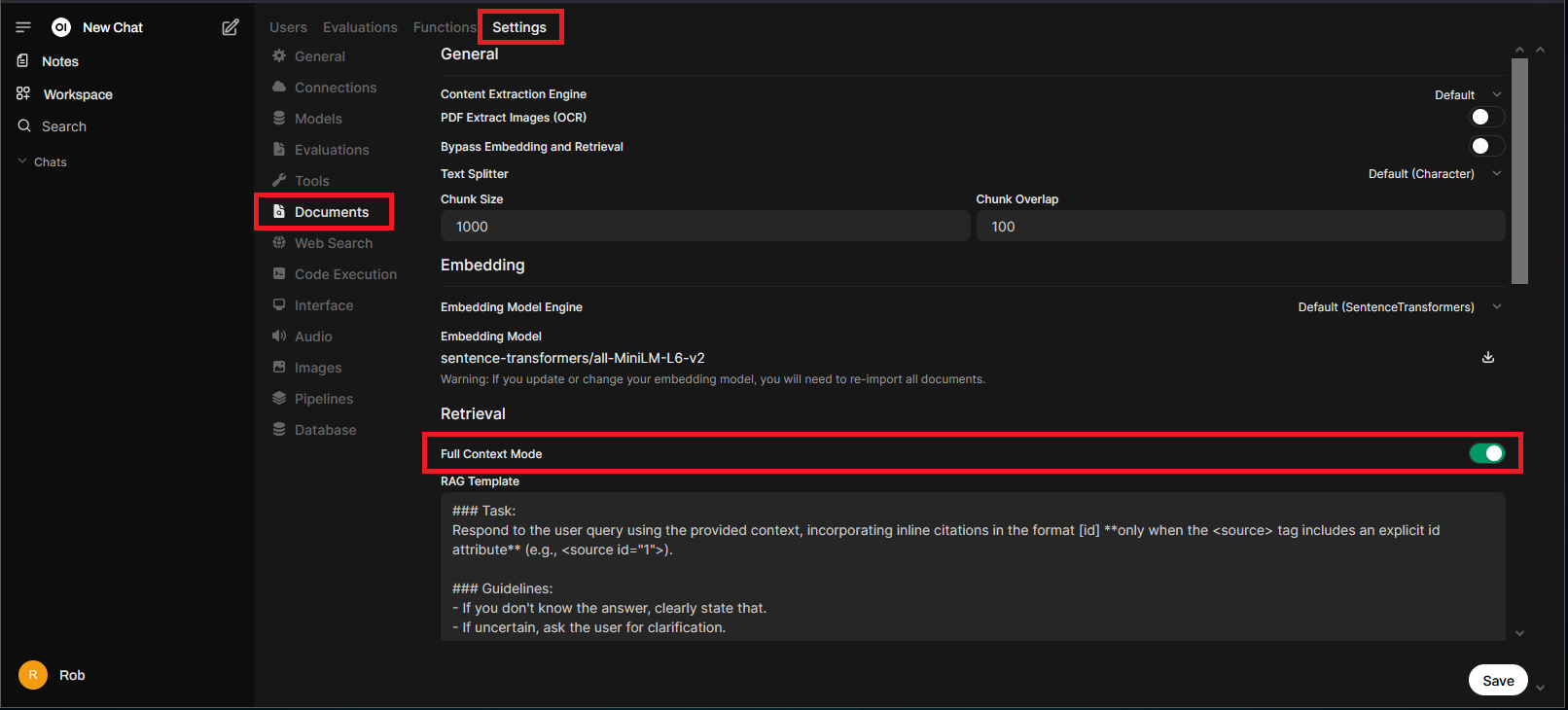
I find this setting particularly useful when using the Web Search features, we will talk about that more in an upcoming section.
Chat Uploads
You can upload files directly into the chat and begin using them immediately. However, these files are only available during the current session and will be deleted with the chat.
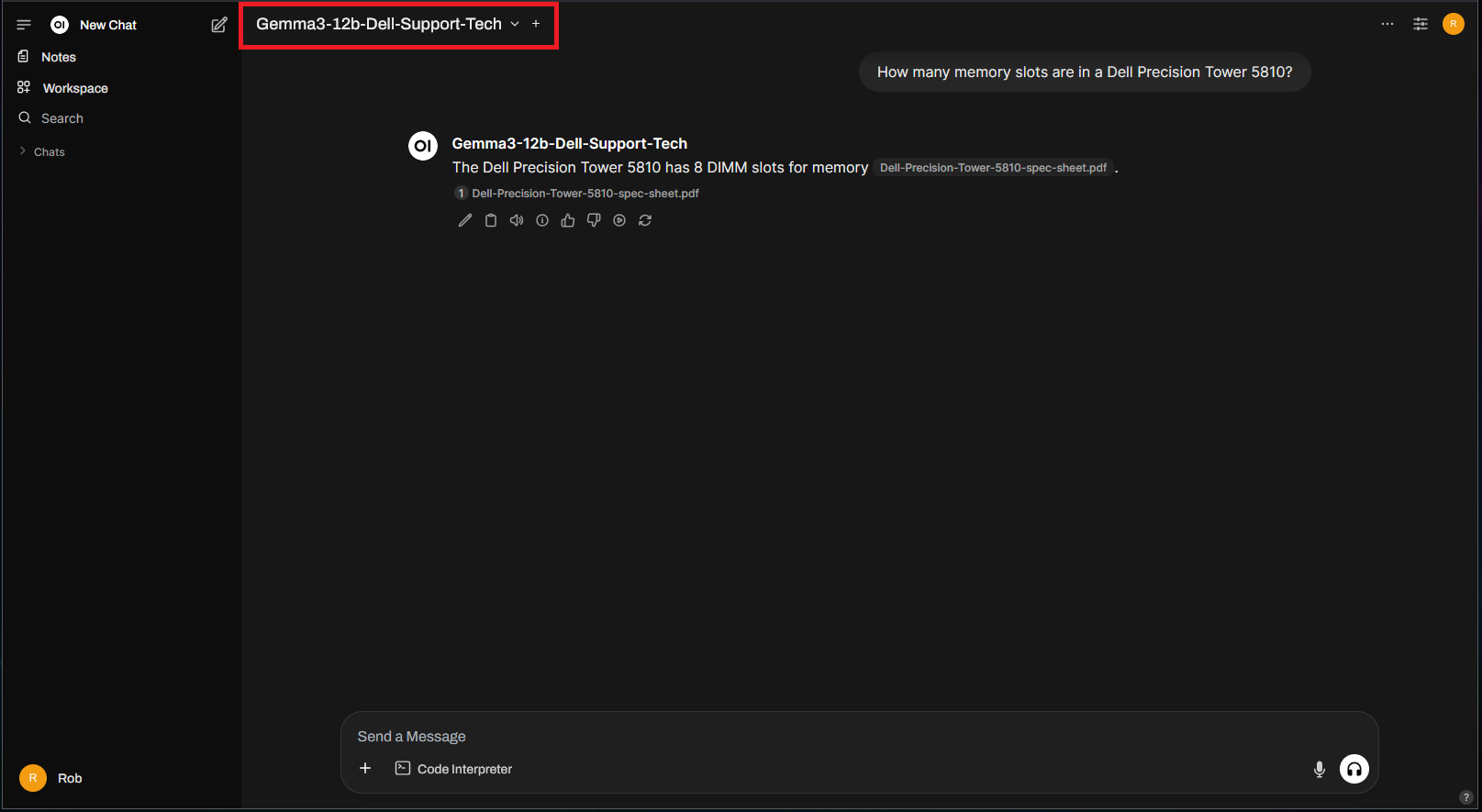
Let’s try asking an obscure question the LLM probably shouldn’t be able to answer, like something you’d find in the owners manual for the Dell Precision powering this project – “How many memory slots are in a Dell Precision Tower 5810?”:
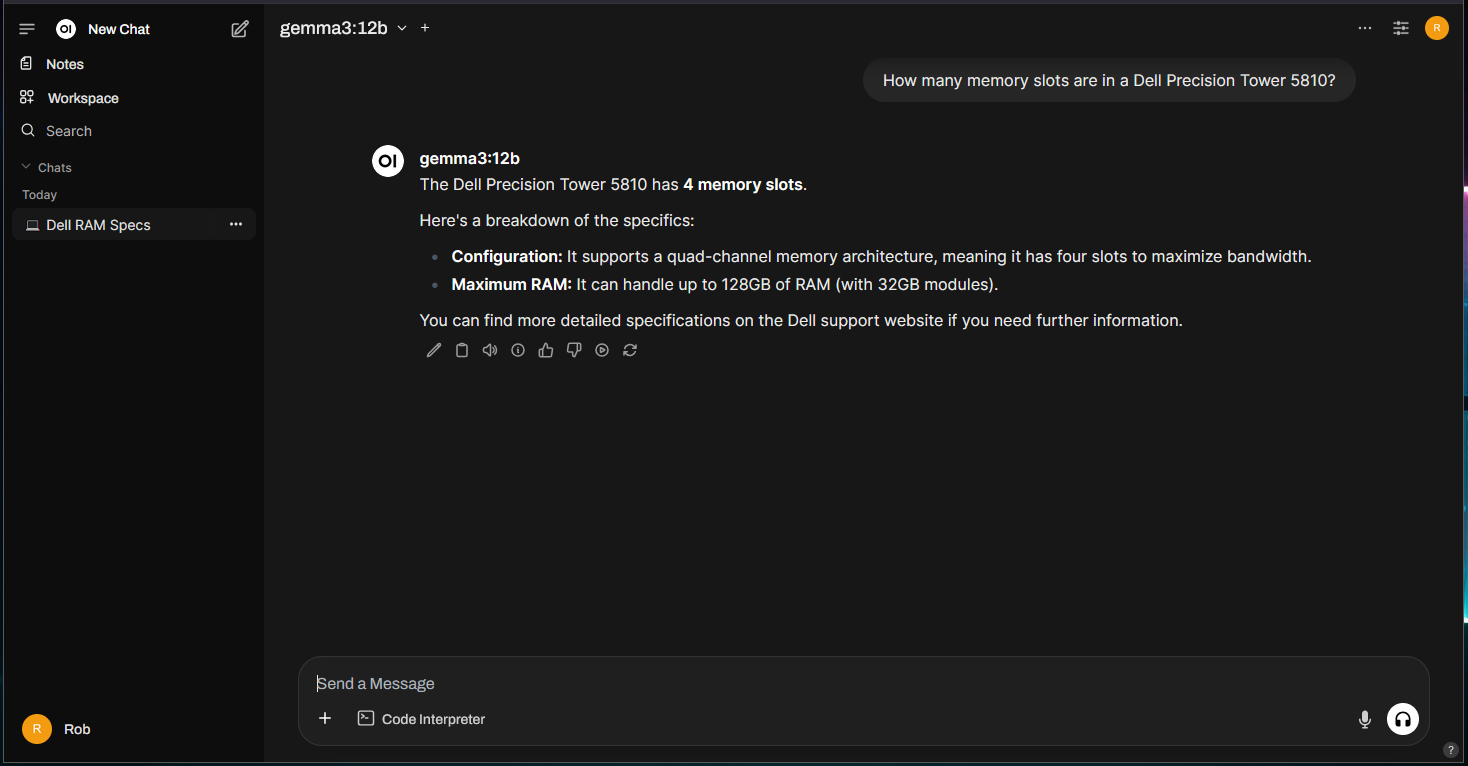
Not quite…
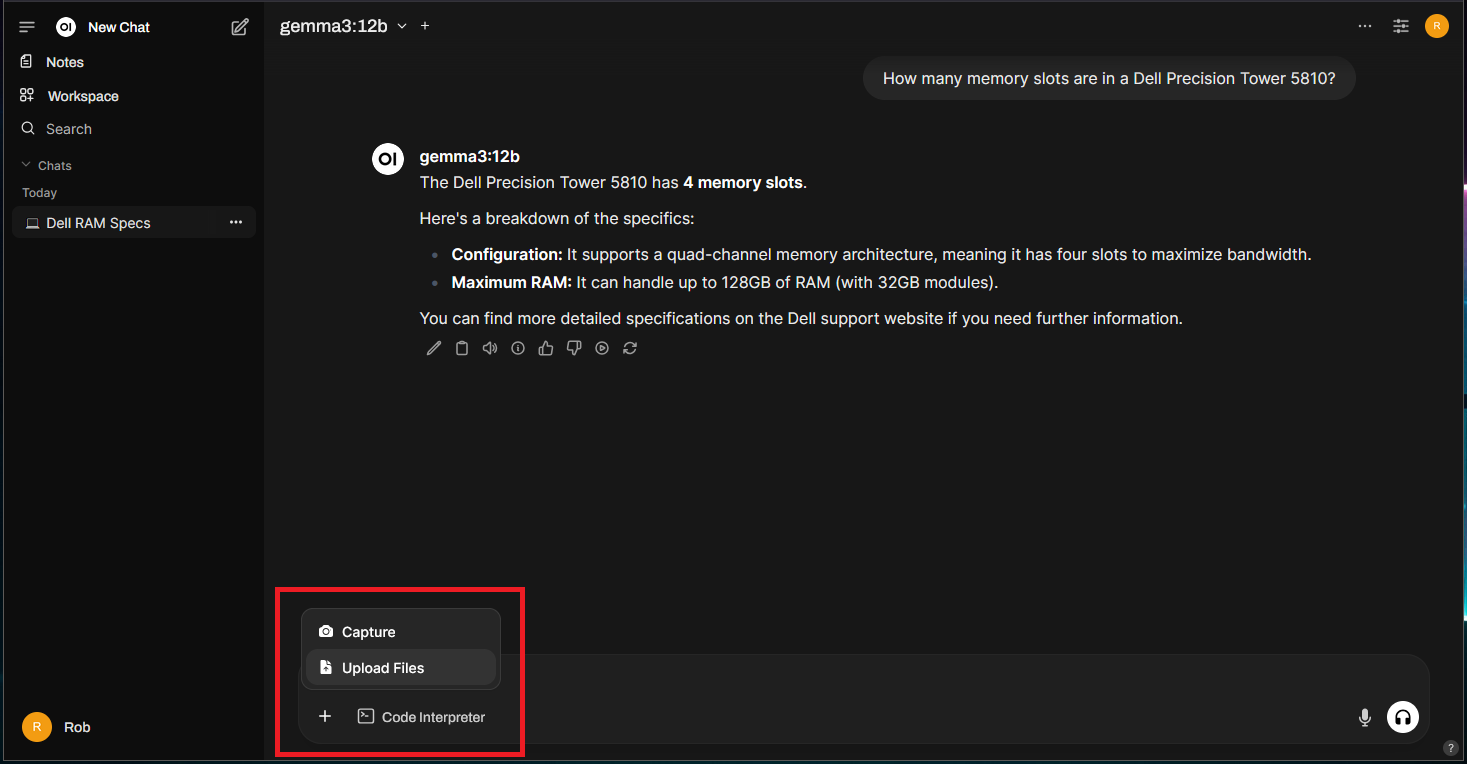
Clicking on the “+” icon in the chat and “Upload Files”, you can upload documents like a pdf:
Asking the same question again:
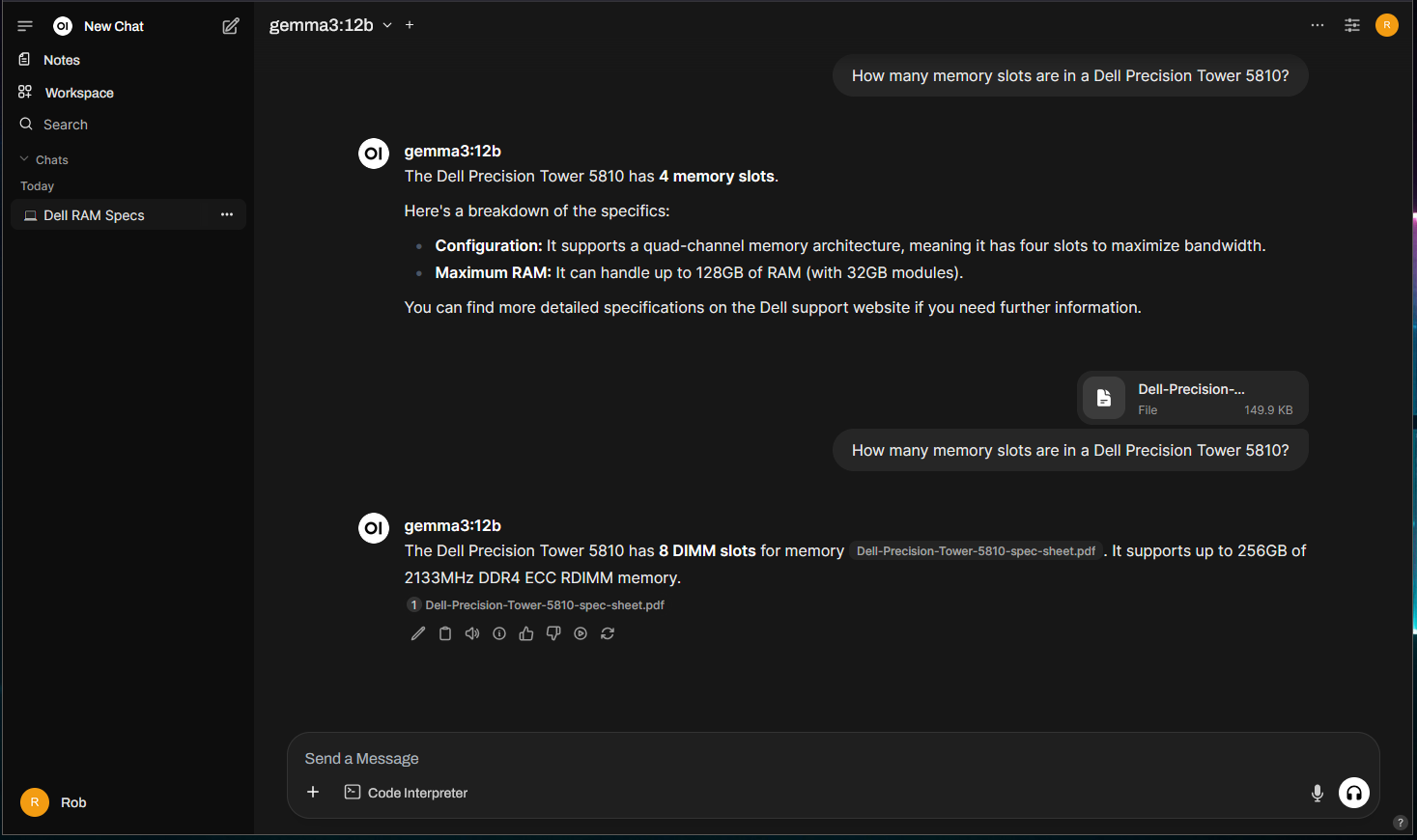
Much better, you don’t know until you know! But if we delete this chat session, the data is gone and which may or may not be desirable.
Knowledge
Knowledge works similar to the chat uploads, but is persistent and consists of a “collection”.
To get started with Knowledge, go to “Workspace” > “Knowledge” and click on the “+” icon:
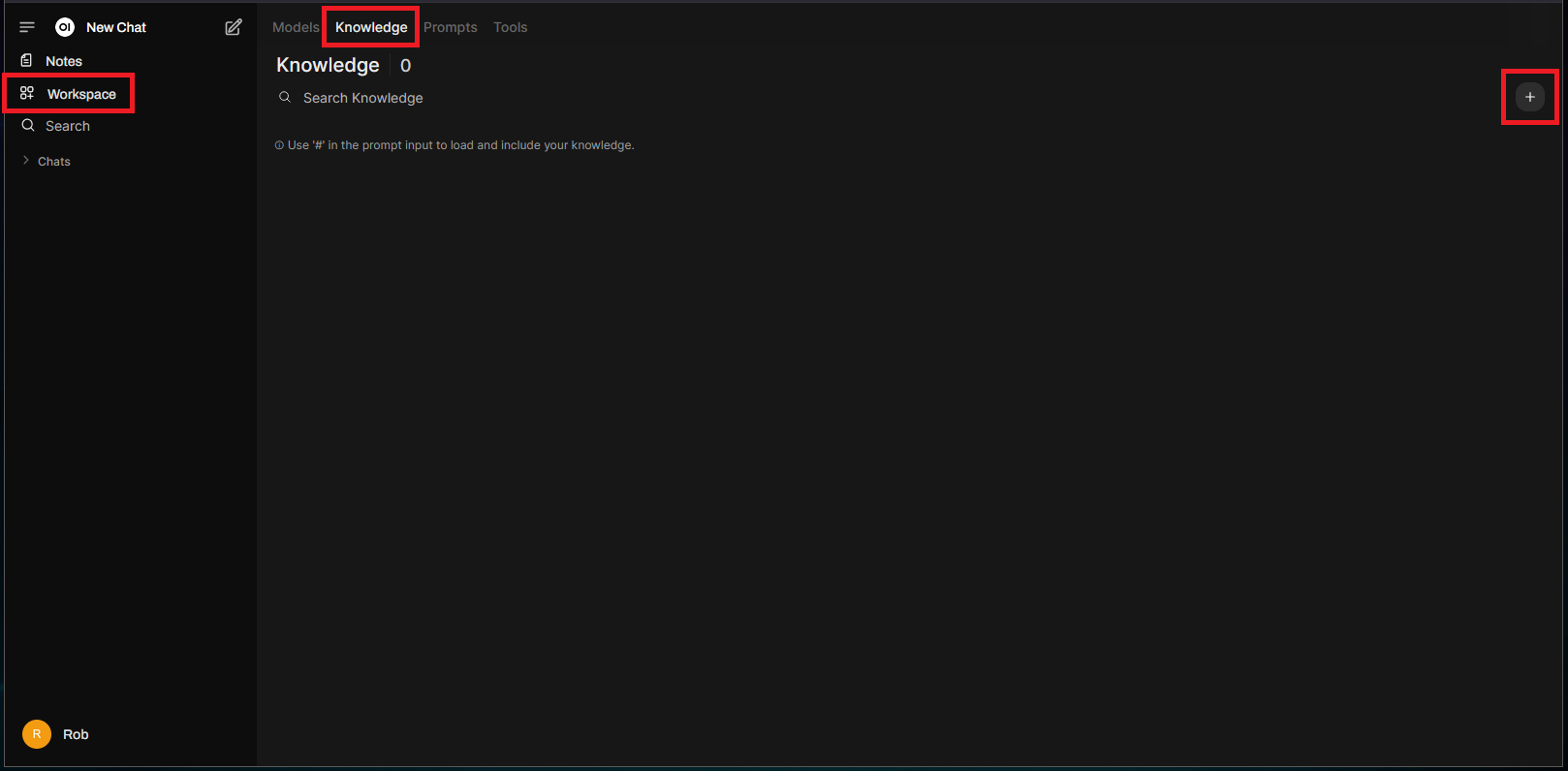
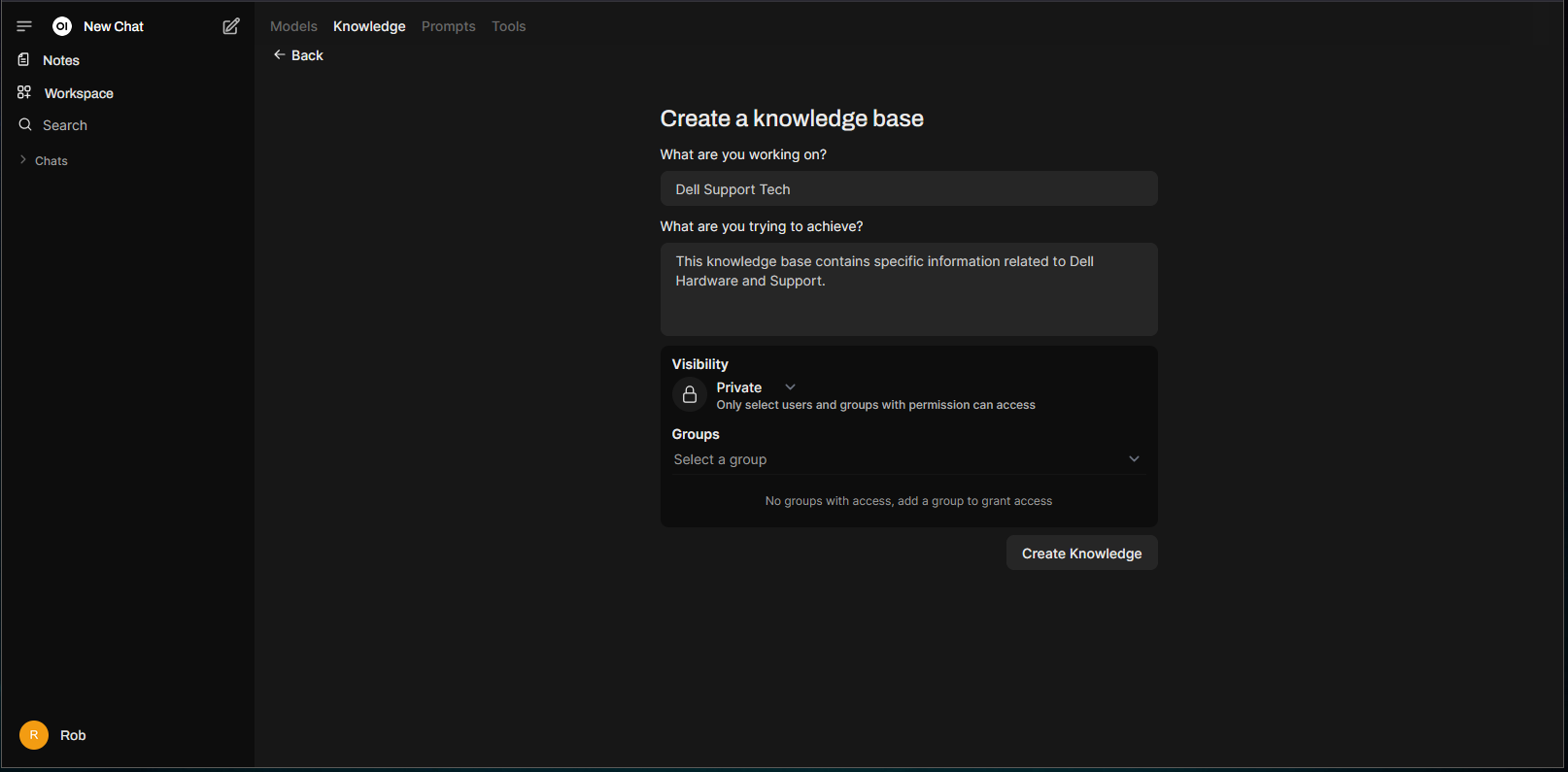
Fill out the form with all the necessary details to begin creating a knowledge base, I’m just going to go with a “Dell Support Tech” theme:
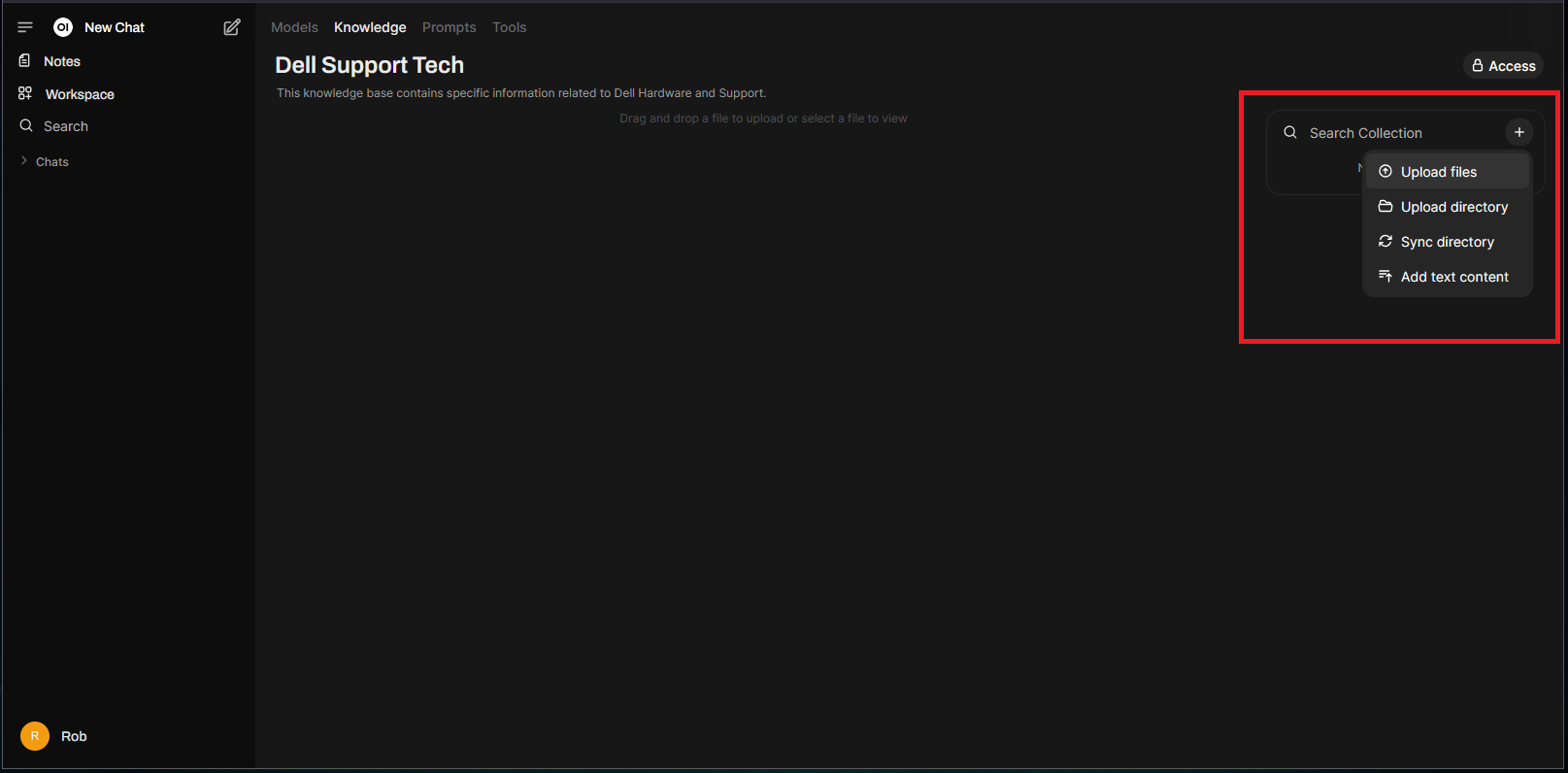
On the right, click the “+” to upload files or even entire directories. Sticking to our example, let’s upload the Dell pdf file:
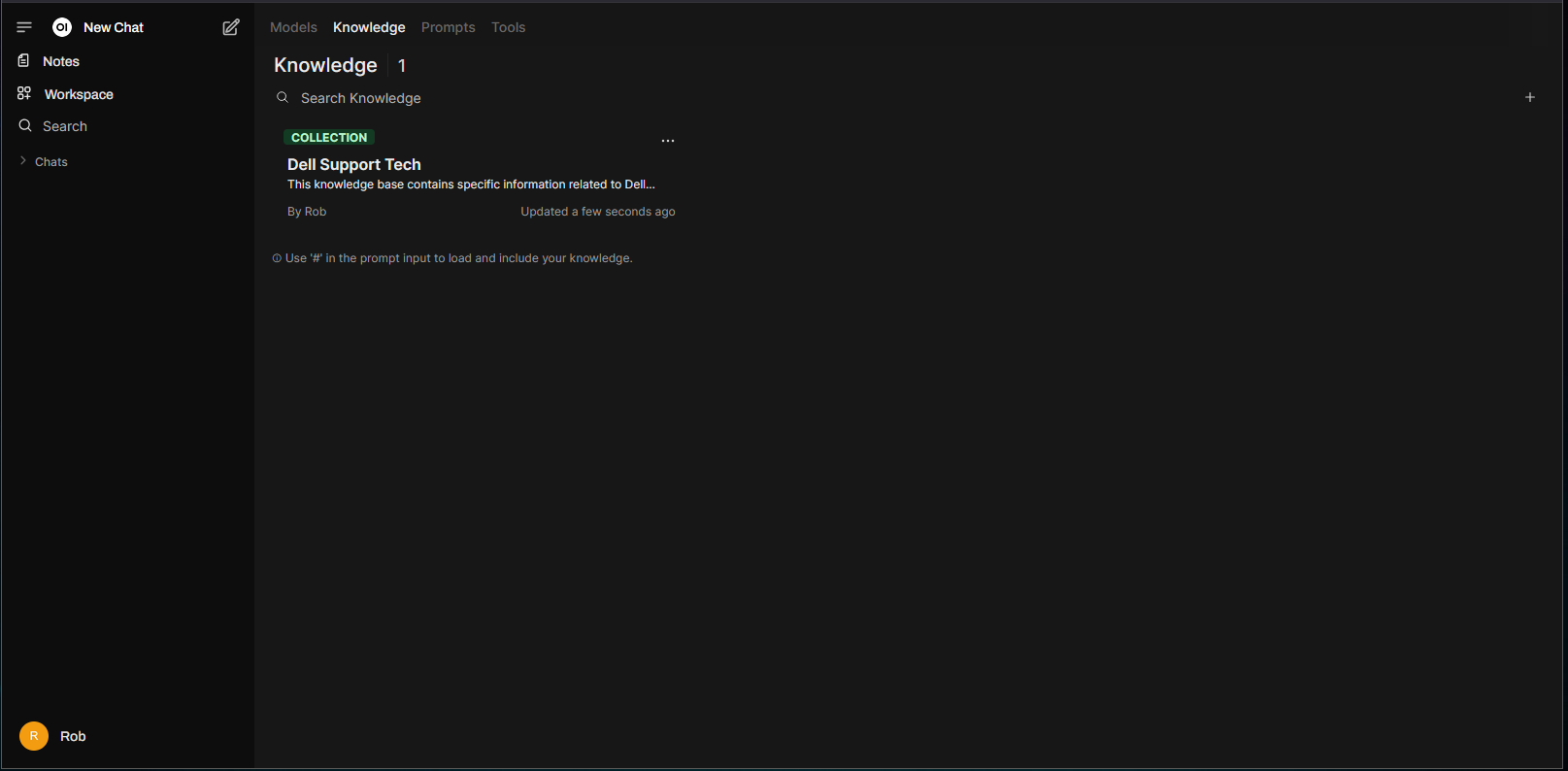
We now have a Knowledge “Collection”:
To leverage the Knowledge Collection, use “#” with the name of the document or collection within a chat session:
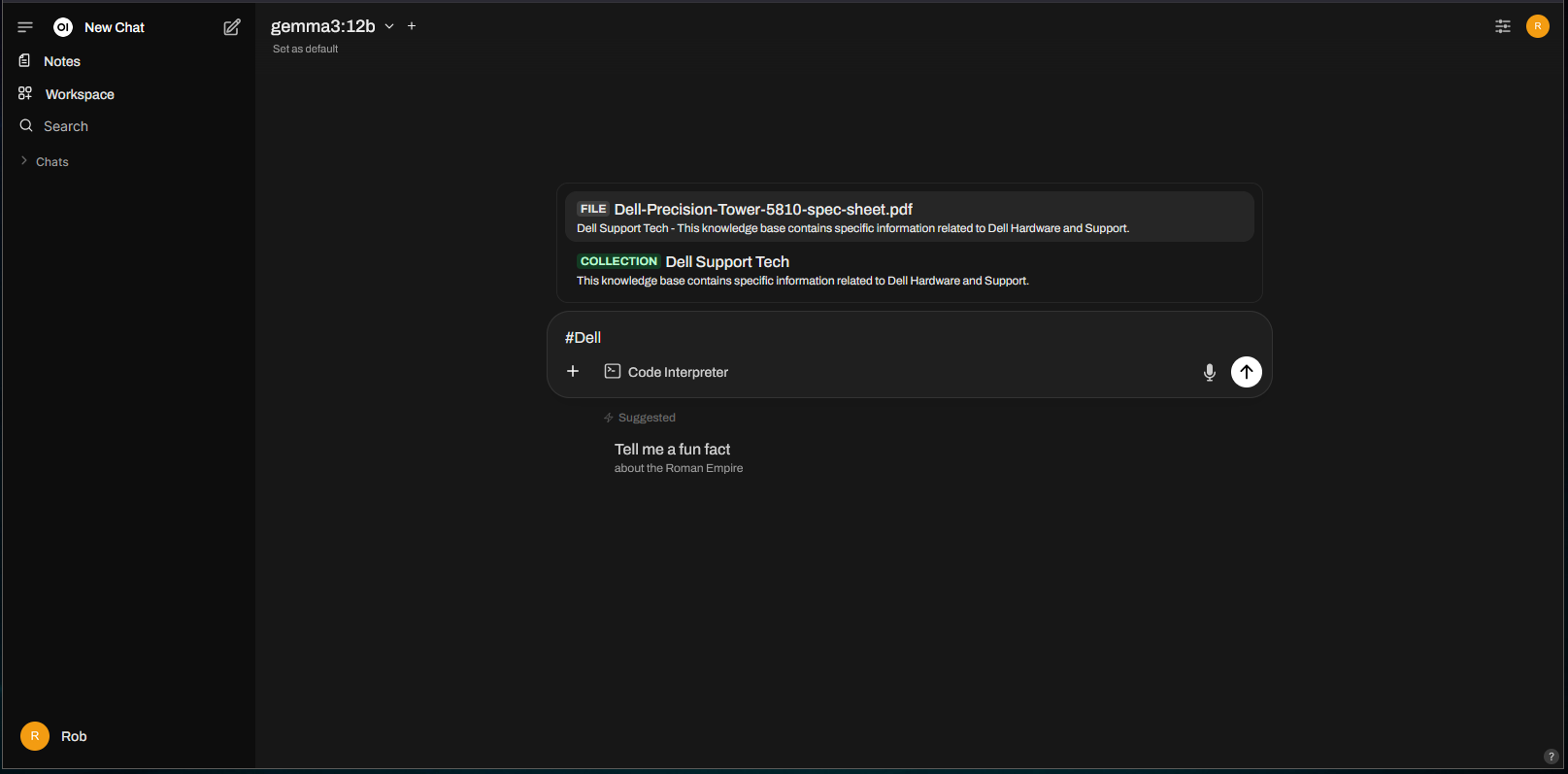
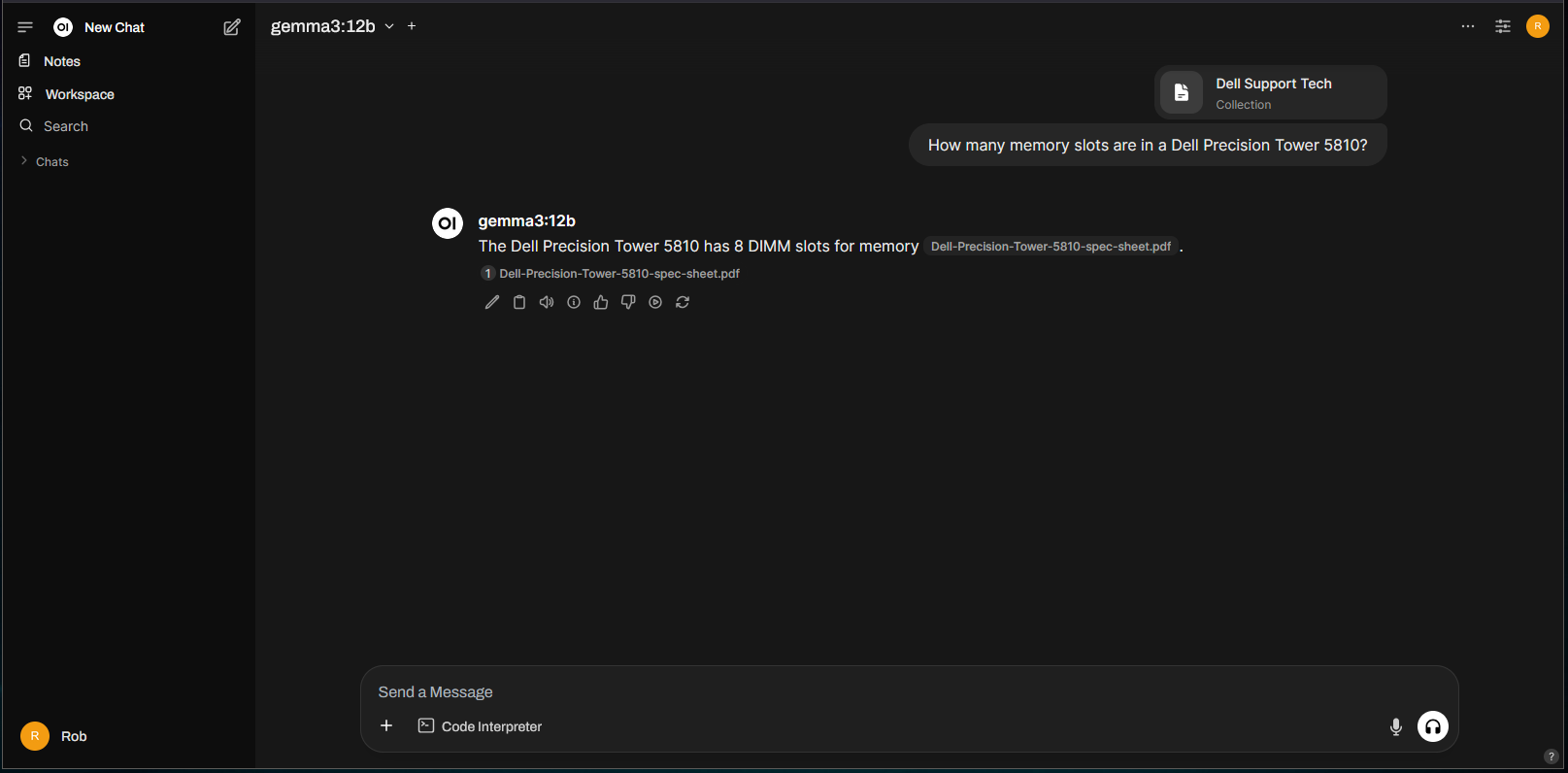
Asking the same question from before, we get the correct response without needing to upload additional documents:
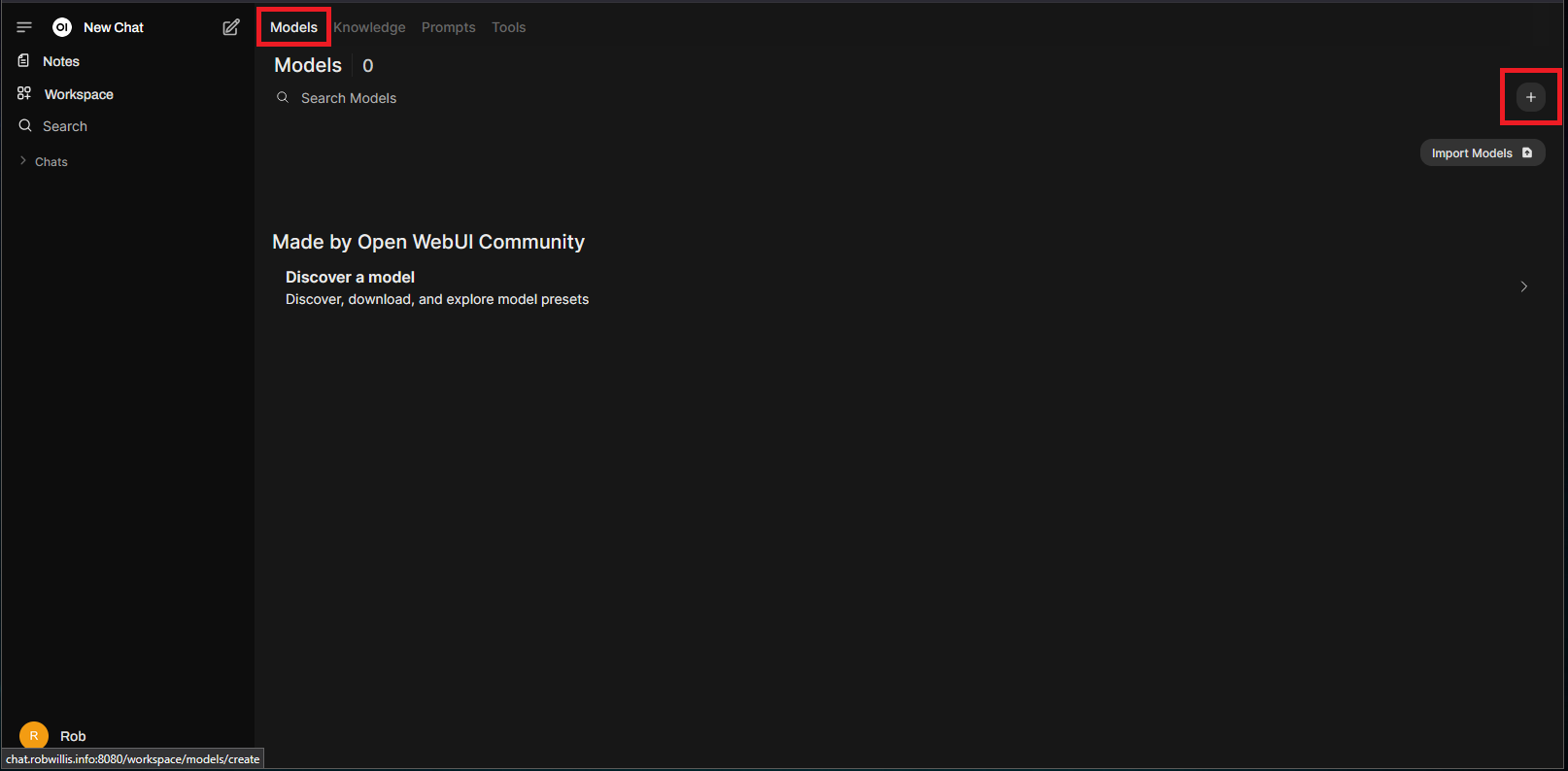
You can also associate the Knowledge with a specific model by going to “Workspace” > “Model” and clicking on the “+” icon:
Name the new model, select a base model and then the knowledge to be associated with it:
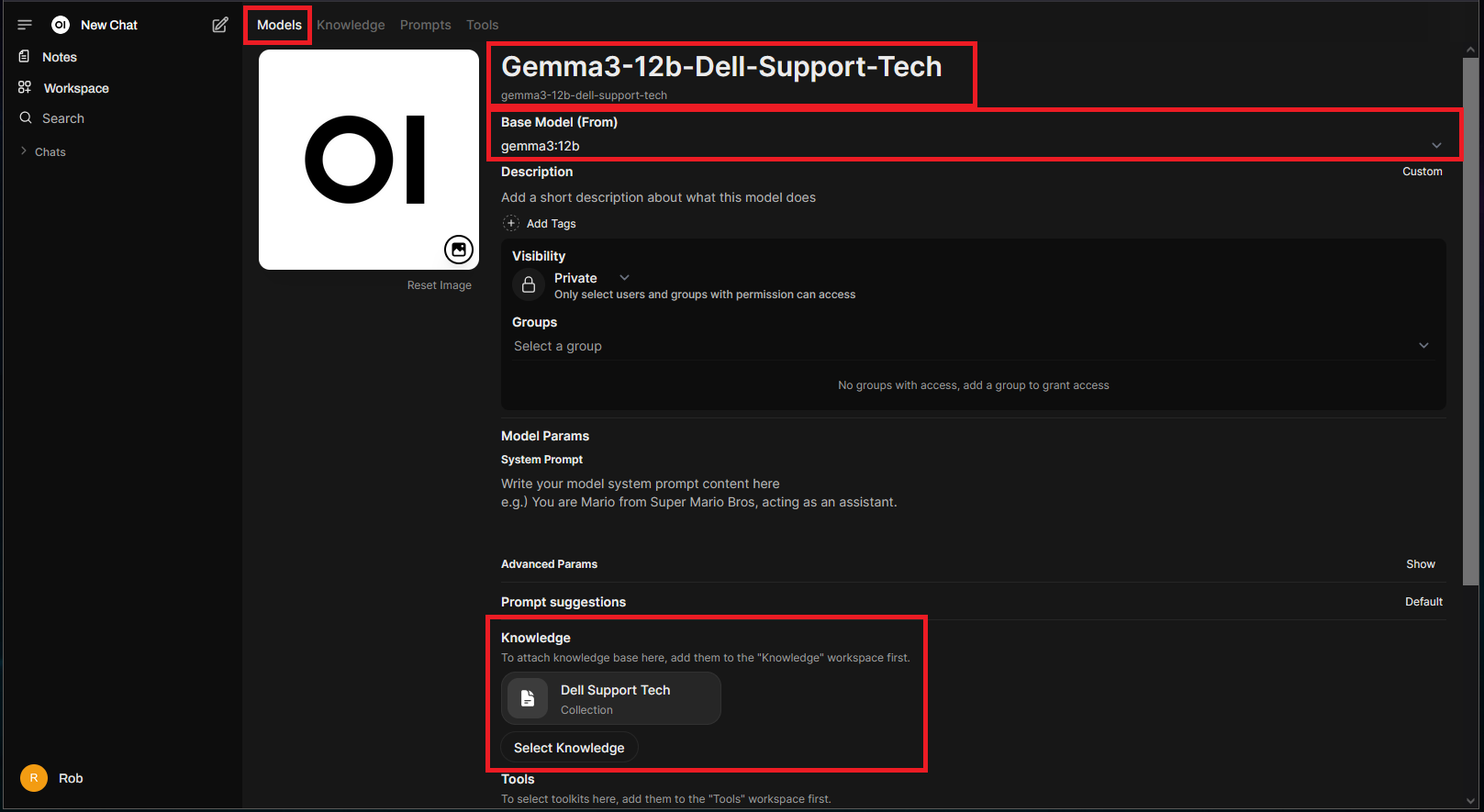
There should now be a new model combined with the knowledge base data:
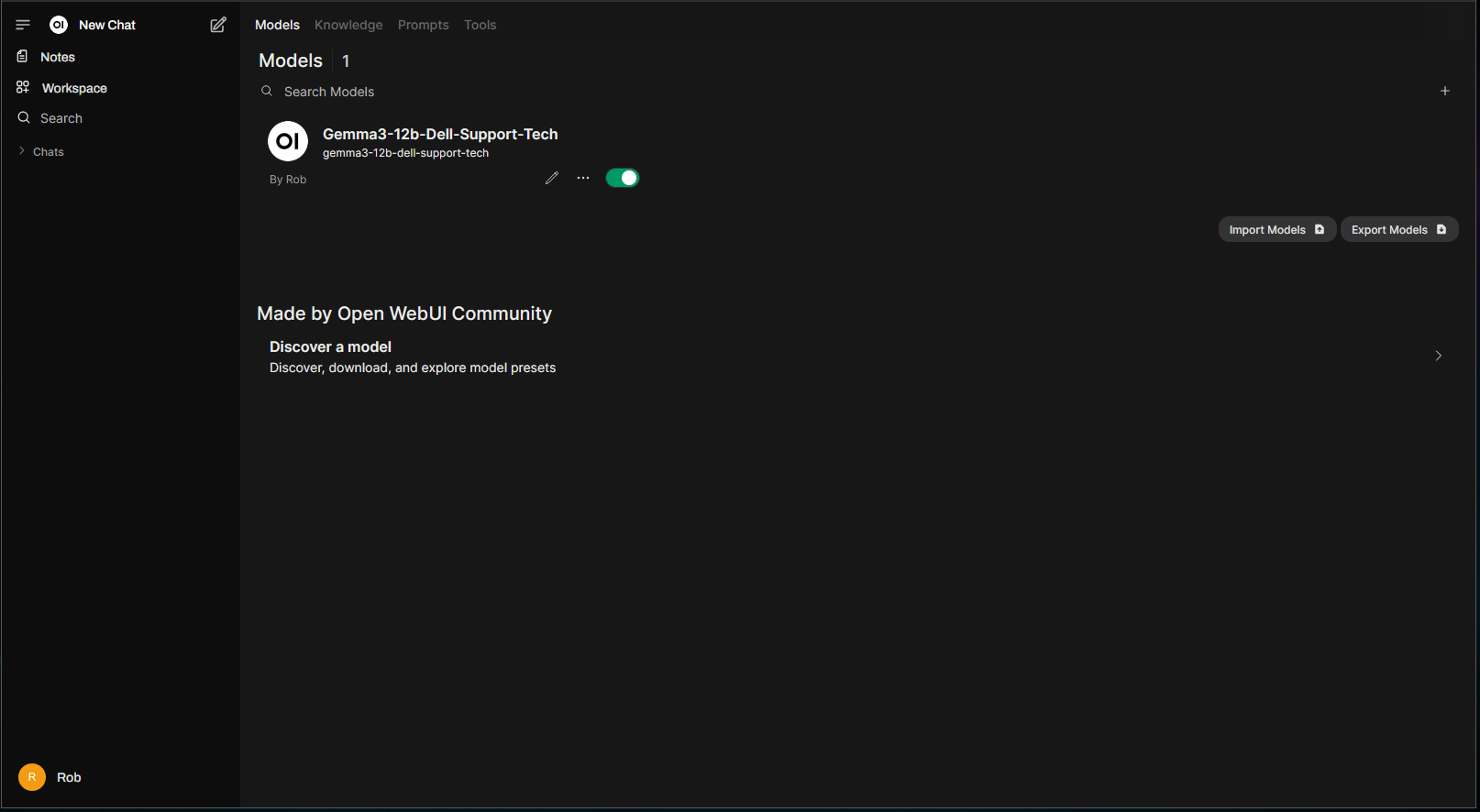
The new model can be selected from the normal chat drop down:
Additional Notes:
- Knowledge Needs To Be Maintained – Make sure to delete old versions of documents after uploading updated versions to prevent stale data.
Web Search Configuration
Web Search is disabled by default. To enable and configure it, navigate to the “Admin Panel” > “Settings” > “Web Search”:
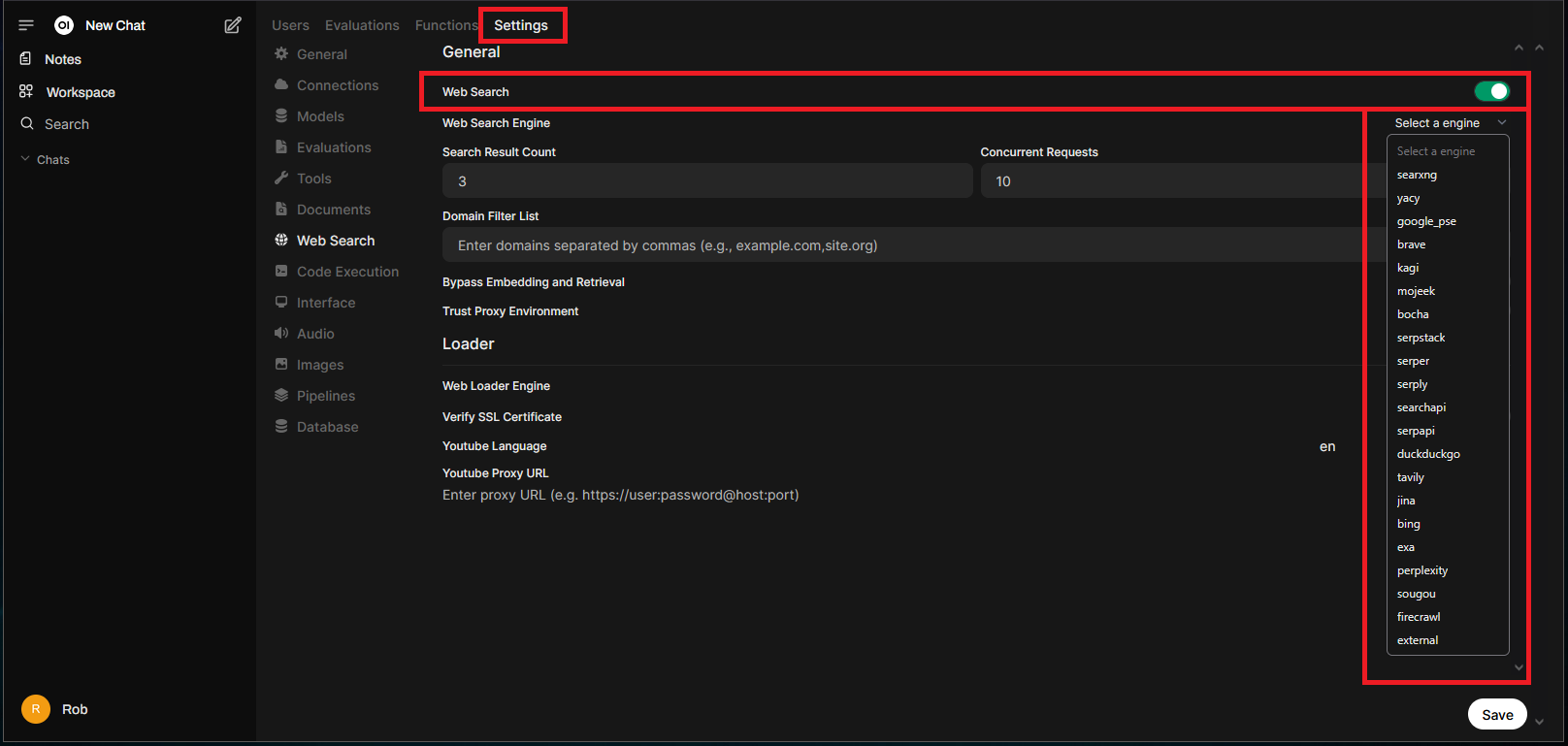
Once enabled, a search engine will need to be selected from the list.
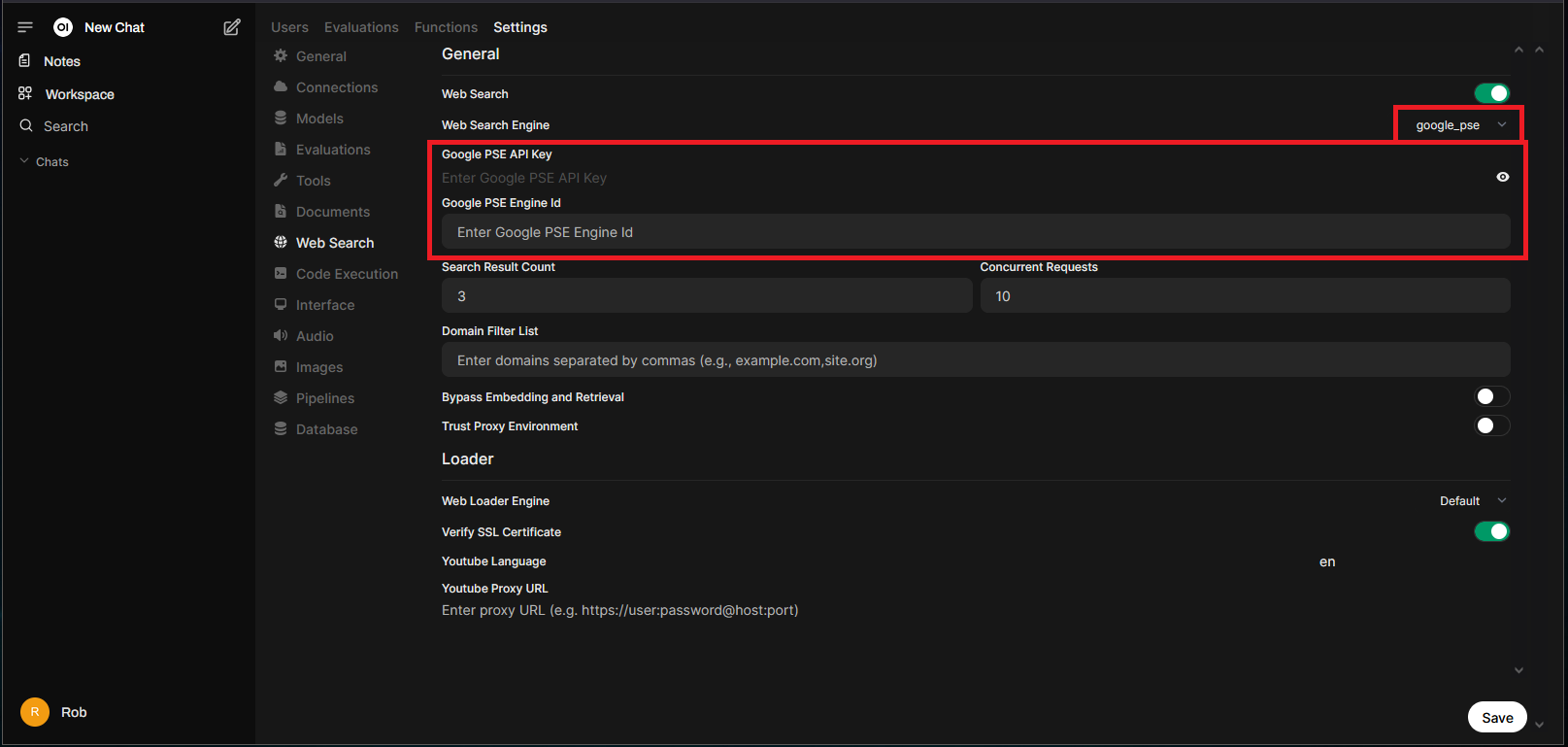
In my experience, Google Programmable Search Engine or “google_pse” tends to provide the most reliable results, but will require an API key. It is free (10k query limit – per day) and accessible via Google account:
https://programmablesearchengine.google.com/
You’ll need to create a new search engine and then add “Programmatic Access” to retrieve the API key.
Plug in the Engine ID/API key and make sure to save the settings:
In the chat session, there should be a new “Web Search” button:
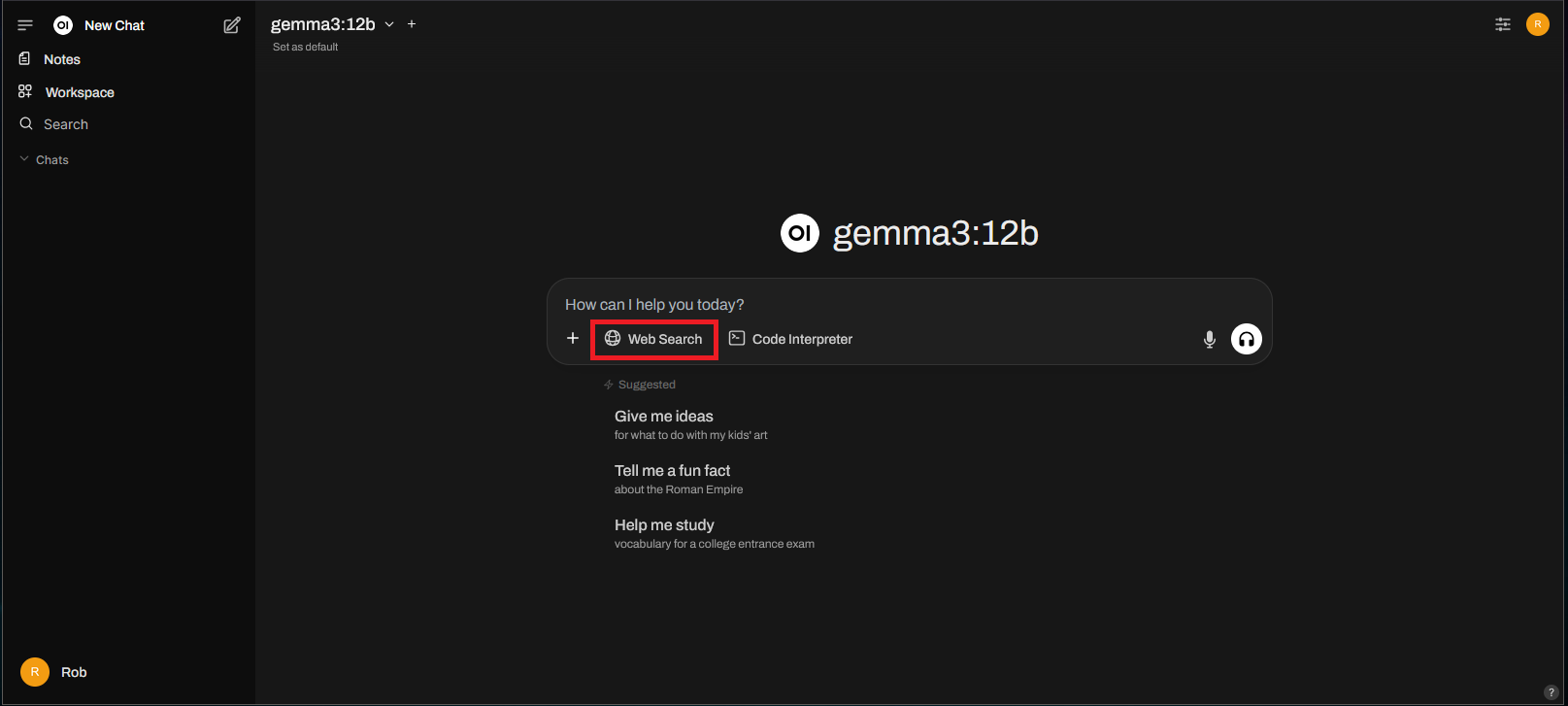
To test it, let’s try asking the model something it shouldn’t know, like what content is currently on the index page of my site?
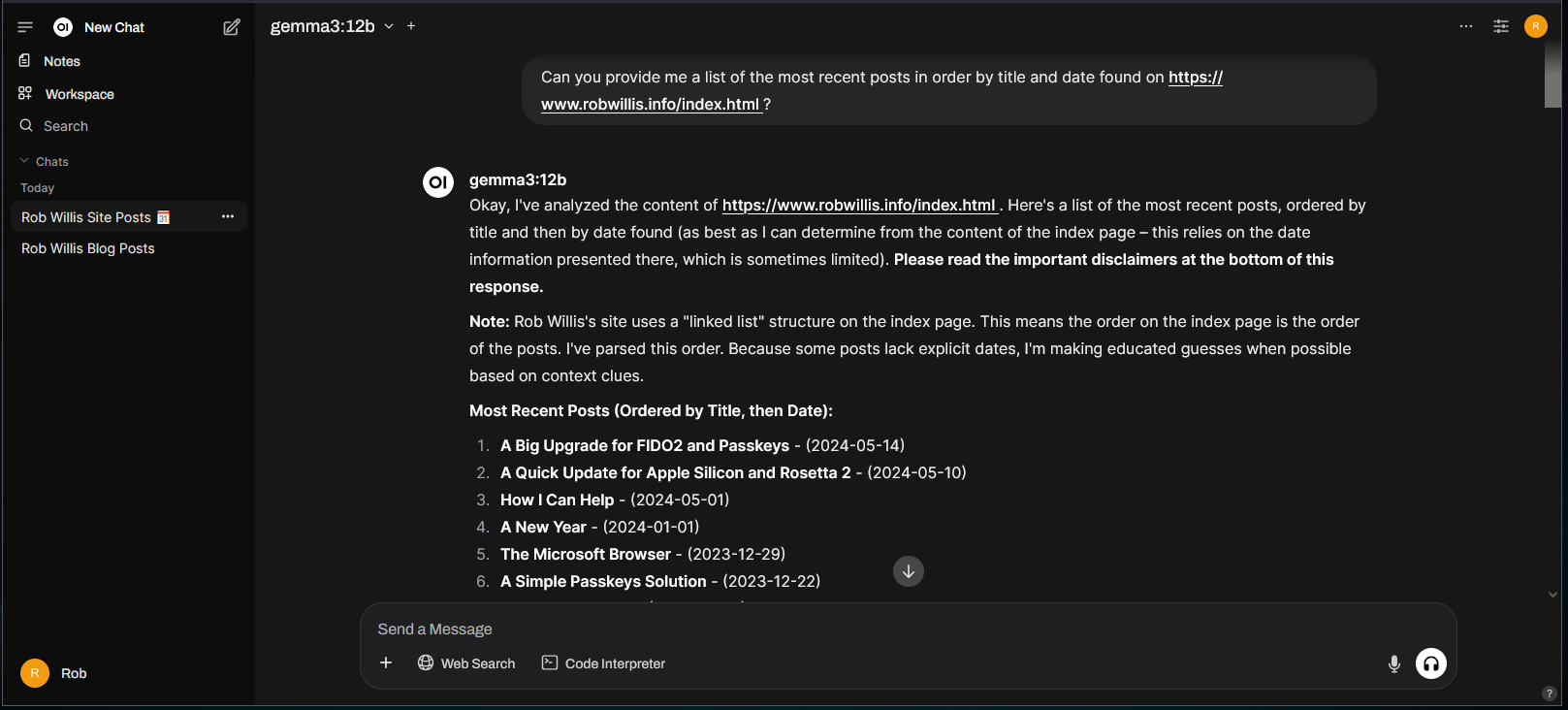
Without the Web Search feature, the model hallucinates all over the place.
Trying the same query again, but enabling the Web Search feature this time:
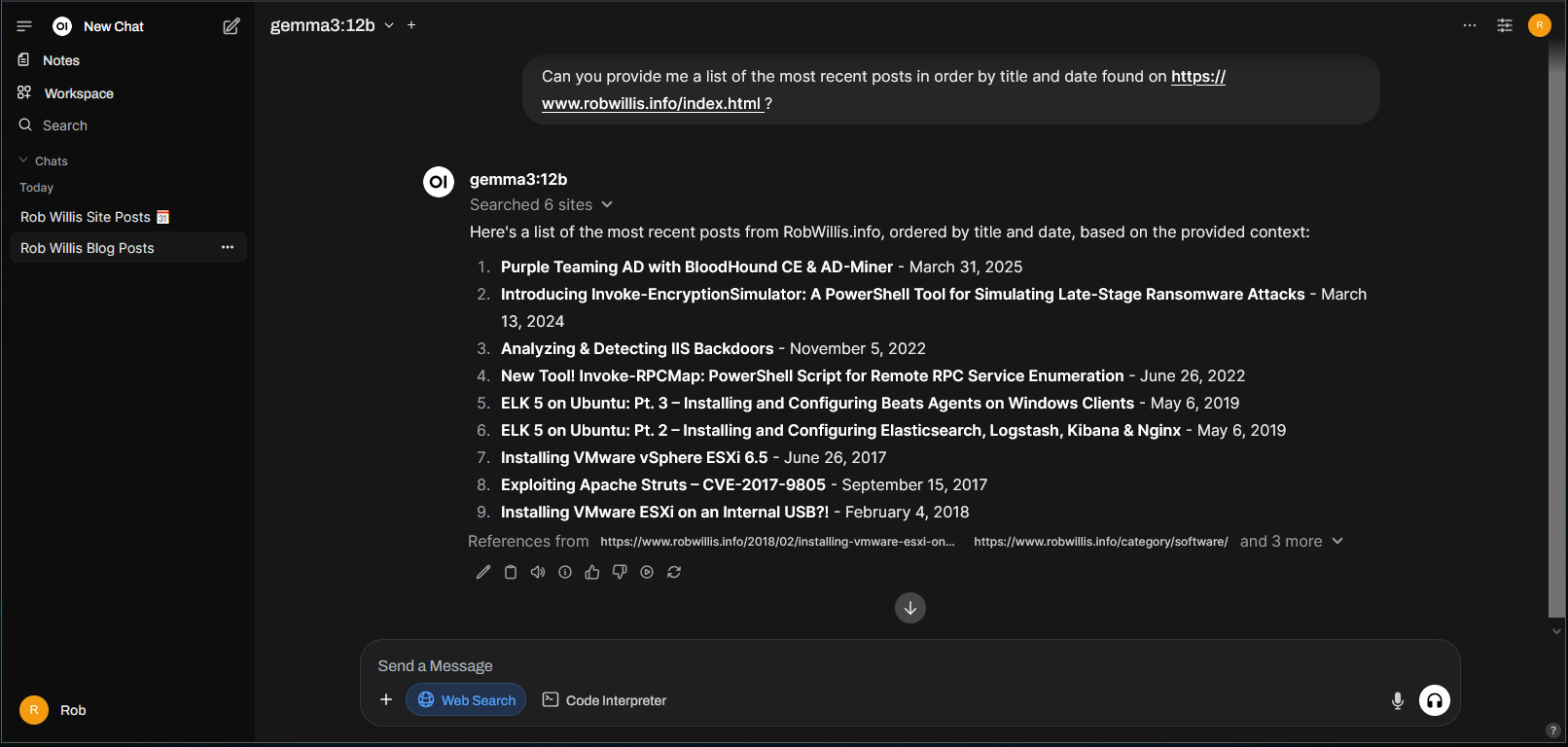
Much better!
Tools, Functions, & Pipelines
This topic is complex enough to be its own post, and I plan to return to it later. For now, I just want to introduce the key concepts to help get started.
If you want to dive deeper, check out the documentation here:
https://docs.openwebui.com/features/plugin/
Overview:
- Tools – Python scripts that extend the functionality of LLMs allowing for collection and analysis of real-time data:
https://openwebui.com/tools - Functions – Extend the functionality of Open WebUI, adding additional Model support or improving usability:
https://openwebui.com/functions - Pipelines – The most advanced but typically not needed option, extends Open WebUI tools and functions into OpenAI API-compatible formats.
Note: Make sure to to exercise caution here, we are talking about running 3rd party code, review any code before executing it.
Again, there’s a ton to unpack here, so I am going to focus on tools since I think they are they most immediately useful of the group. What makes tools interesting is up until this point, this whole system has been text-in, text-out. Tools allow the LLMs to start interacting with the world beyond that.
To get started, you’ll want to make sure to sign up for an Open WebUI community account, once logged in you should see something similar to the following:
Select a tool to view more detailed information:
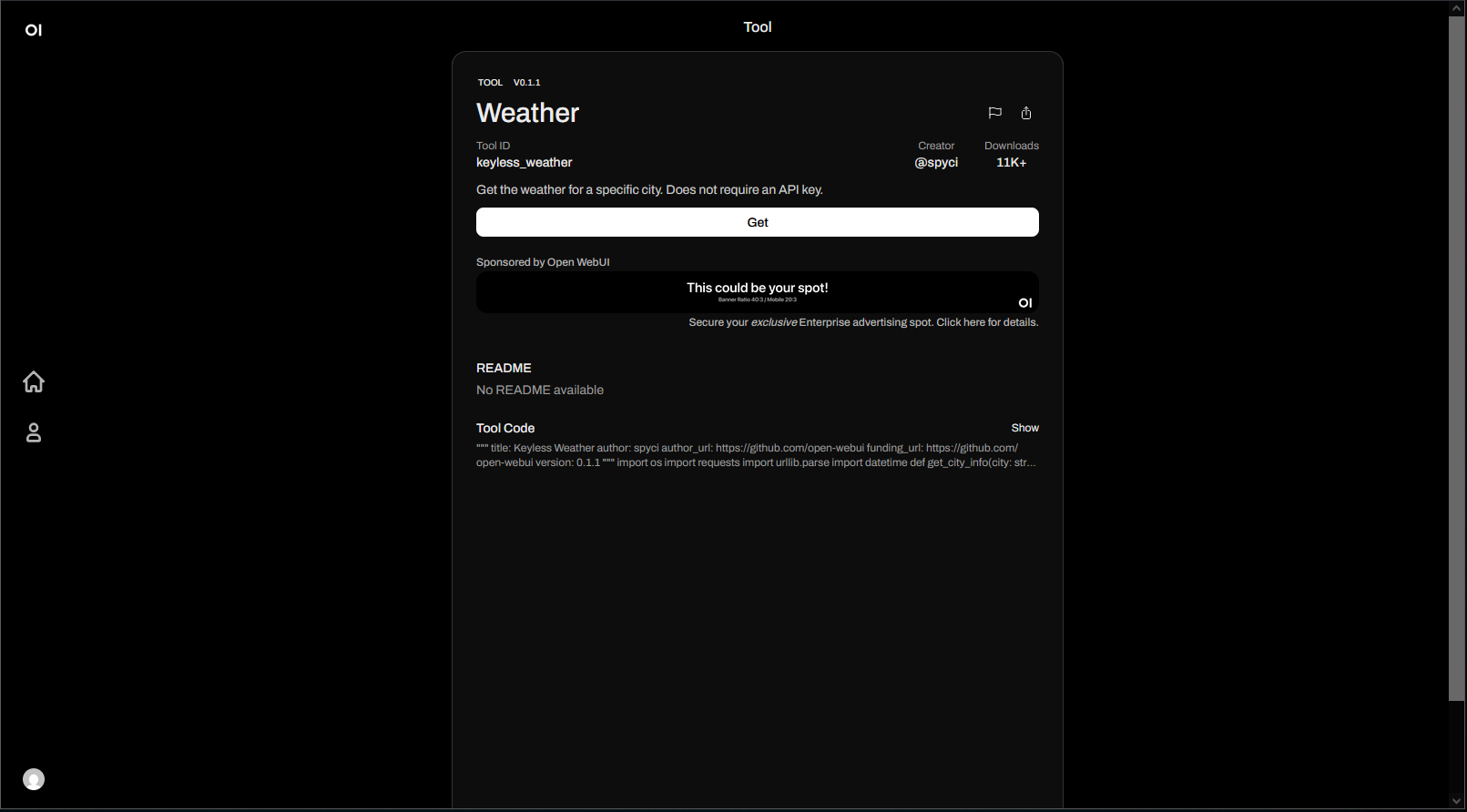
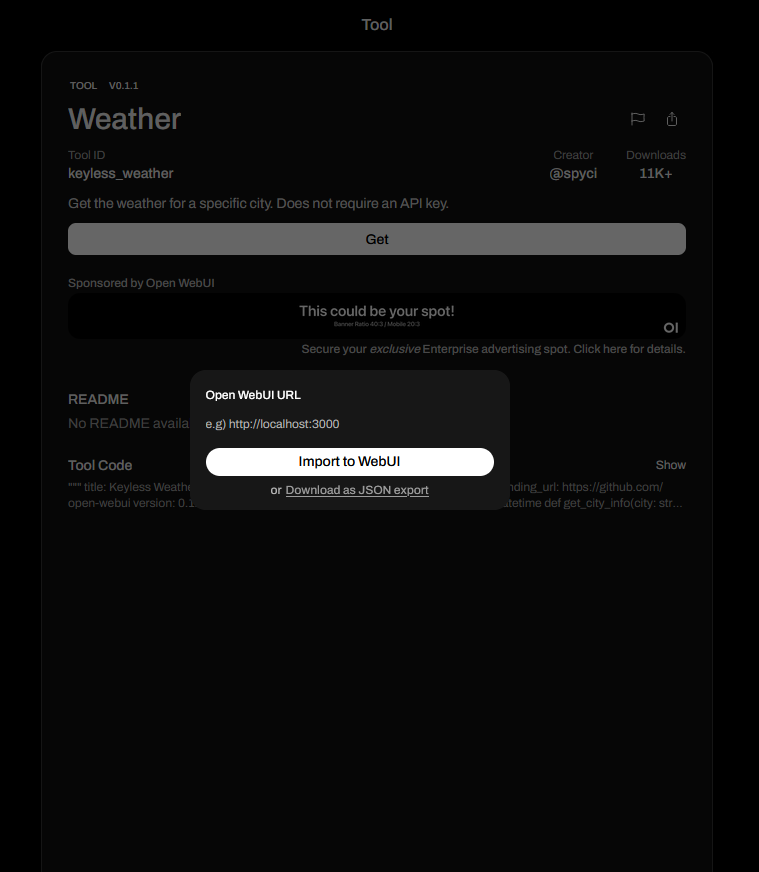
Clicking “Get” will display a popup allowing you to either import the tool directly into the Open WebUI instance or download it as a JSON export:
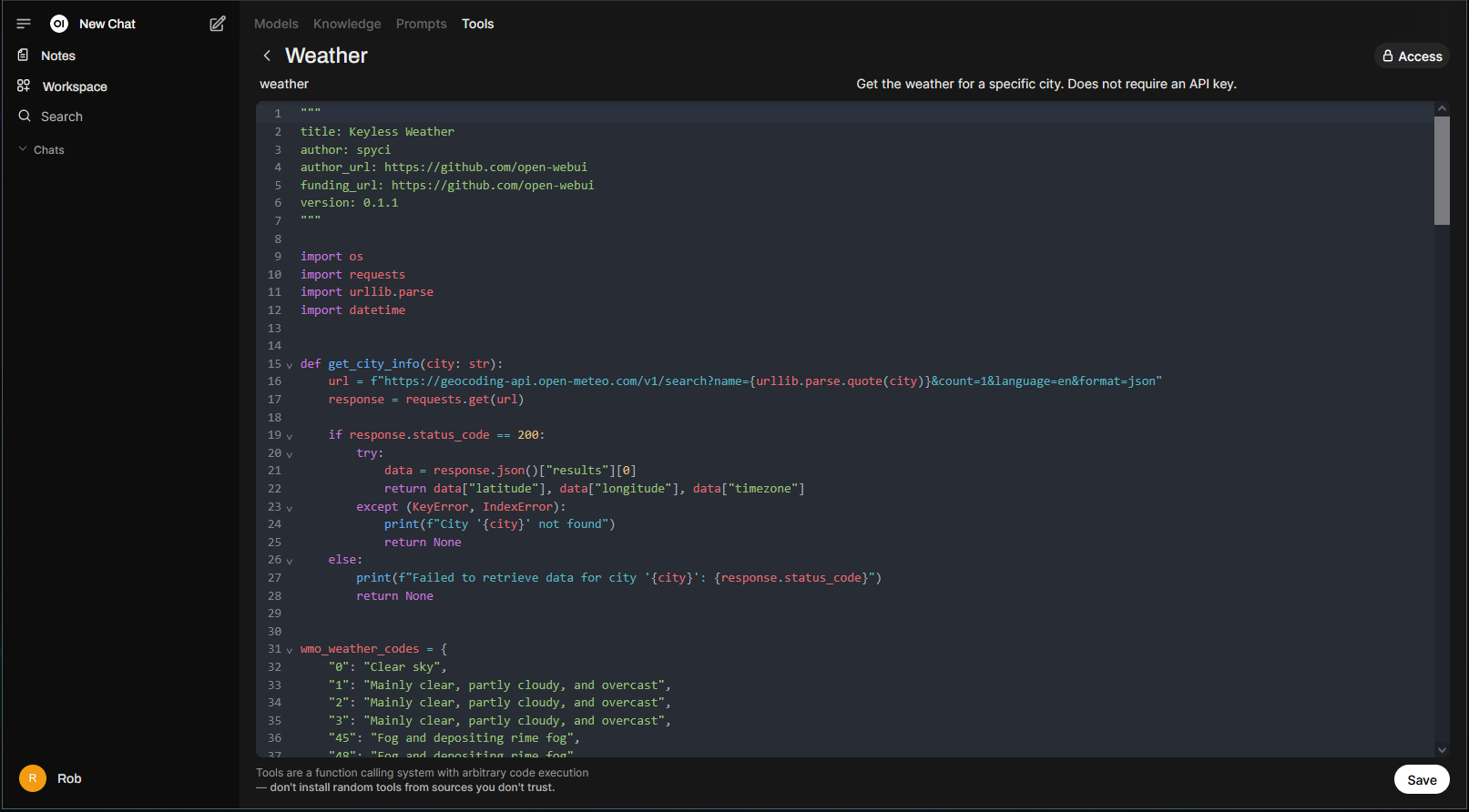
When importing the tool into Open WebUI, you are presented with the opportunity to review the code:
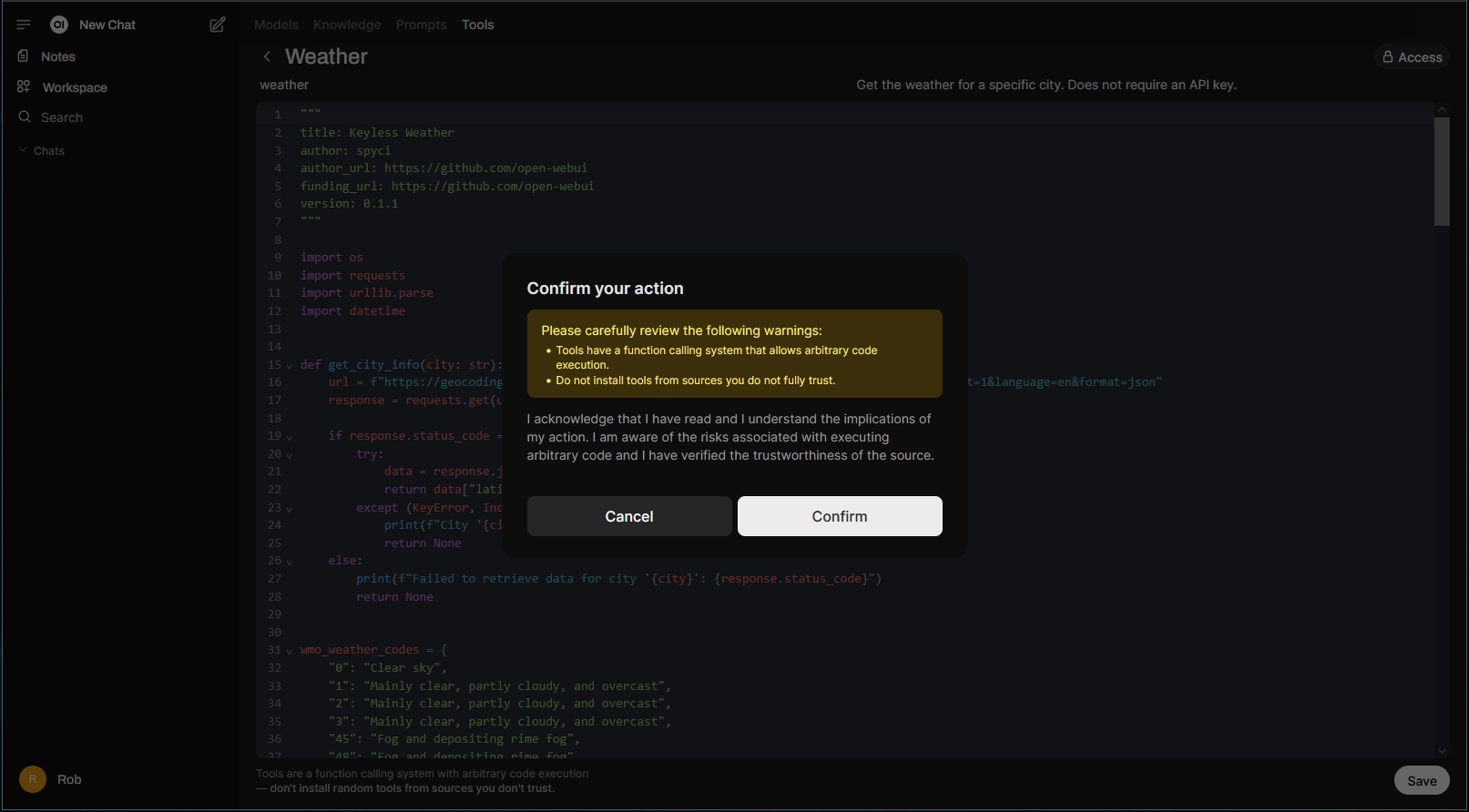
And then an additional reminder to verify the code’s trustworthiness before saving:
Navigating to “Workspace” > “Tools”, shows all of the currently available tools along with the ability to import and create new tools (“+”):
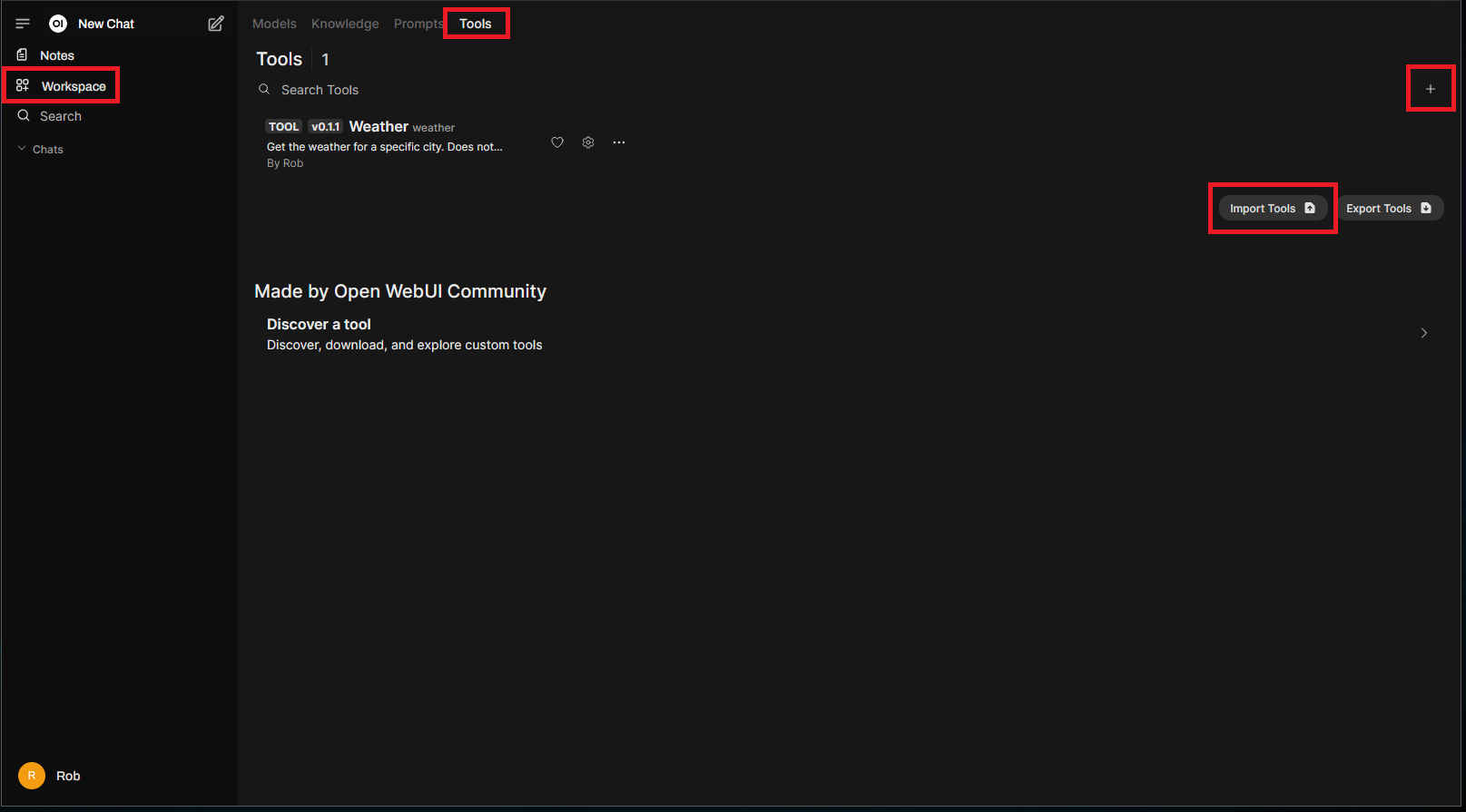
To use a tool, return to the main chat area and click the “+”. You should then see new options available, such as the weather tool in this example:
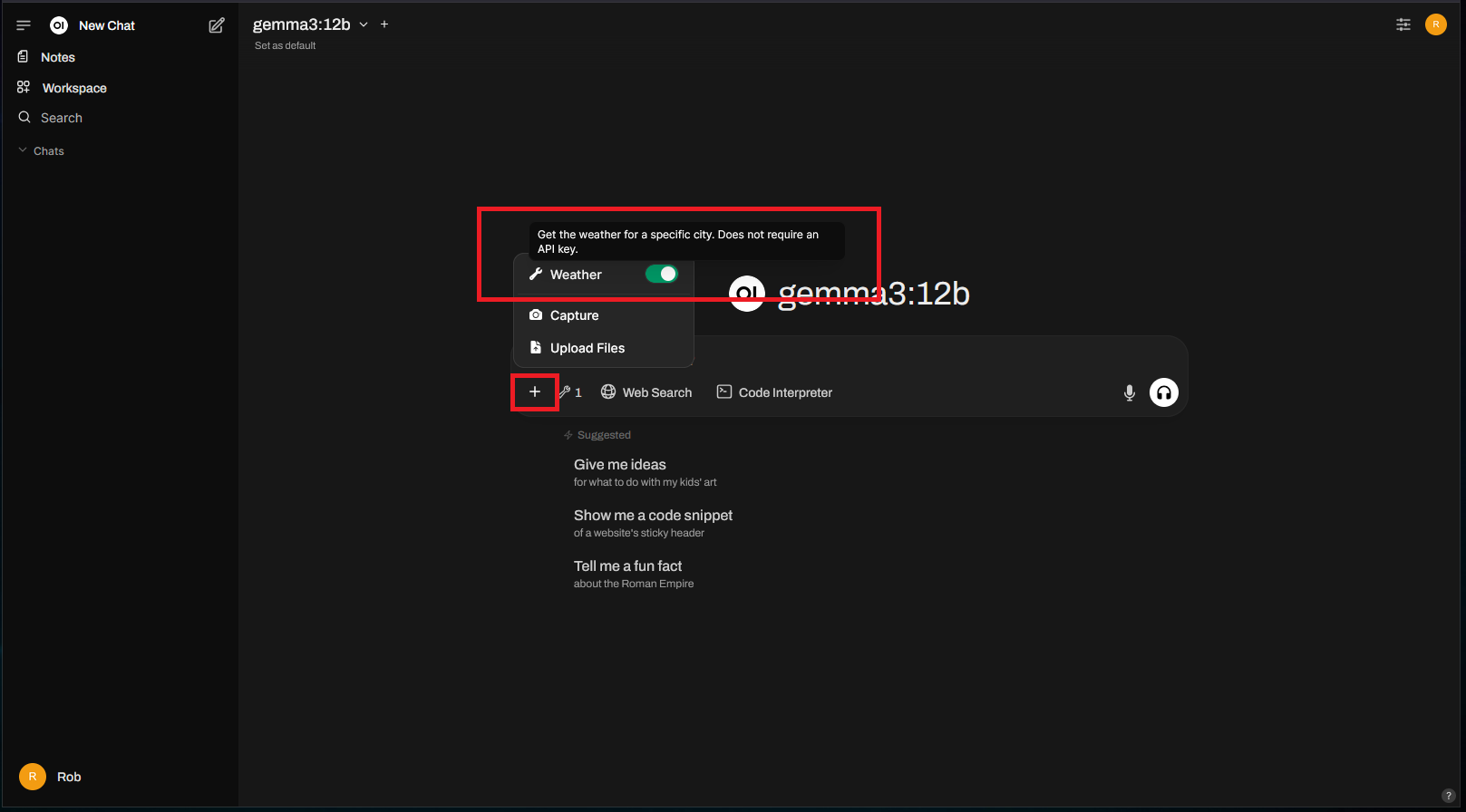
To test it out, let’s try asking about the weather without using the new weather tool:
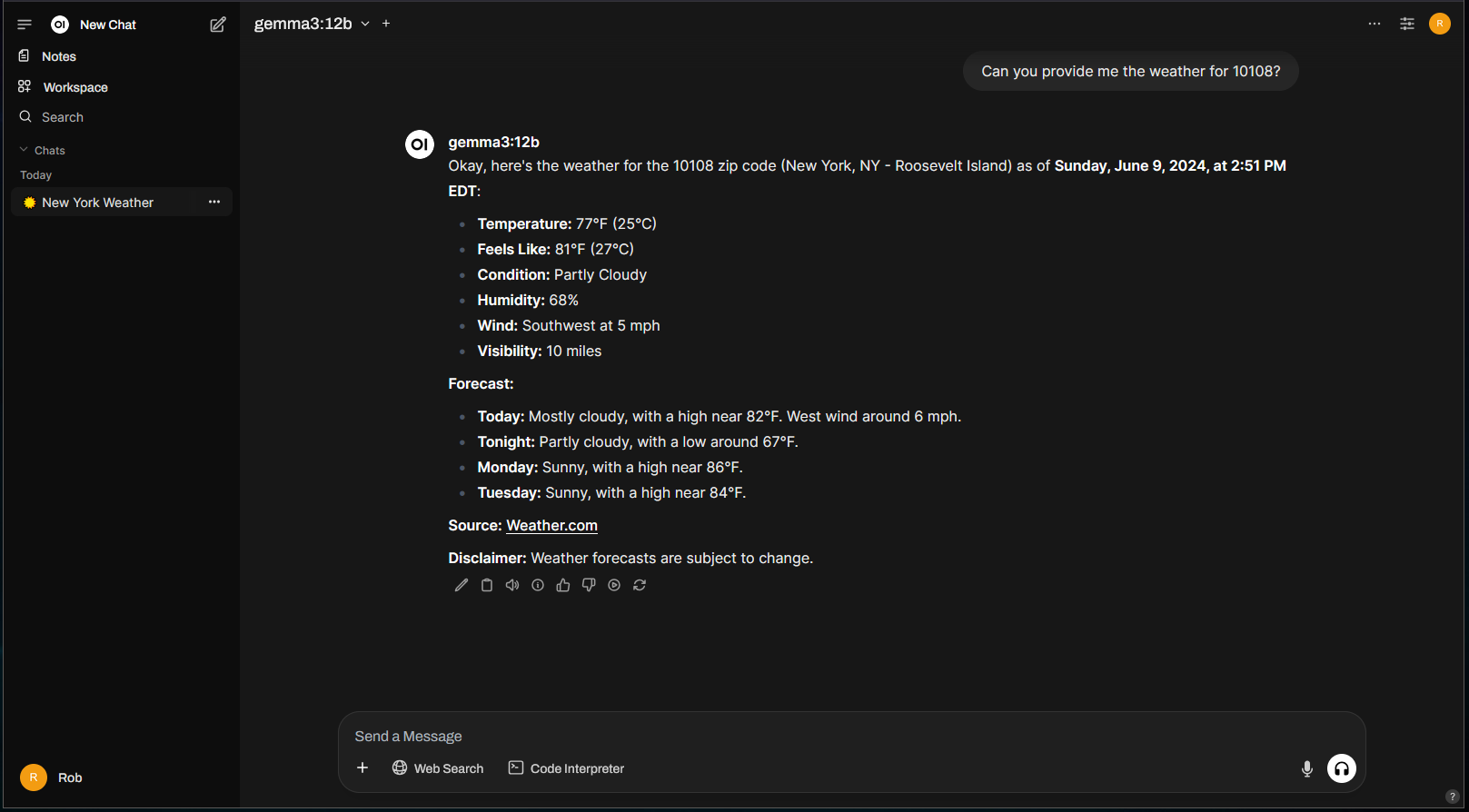
It doesn’t know what day it is. 🙂
Now to try it again, but calling the weather tool this time:
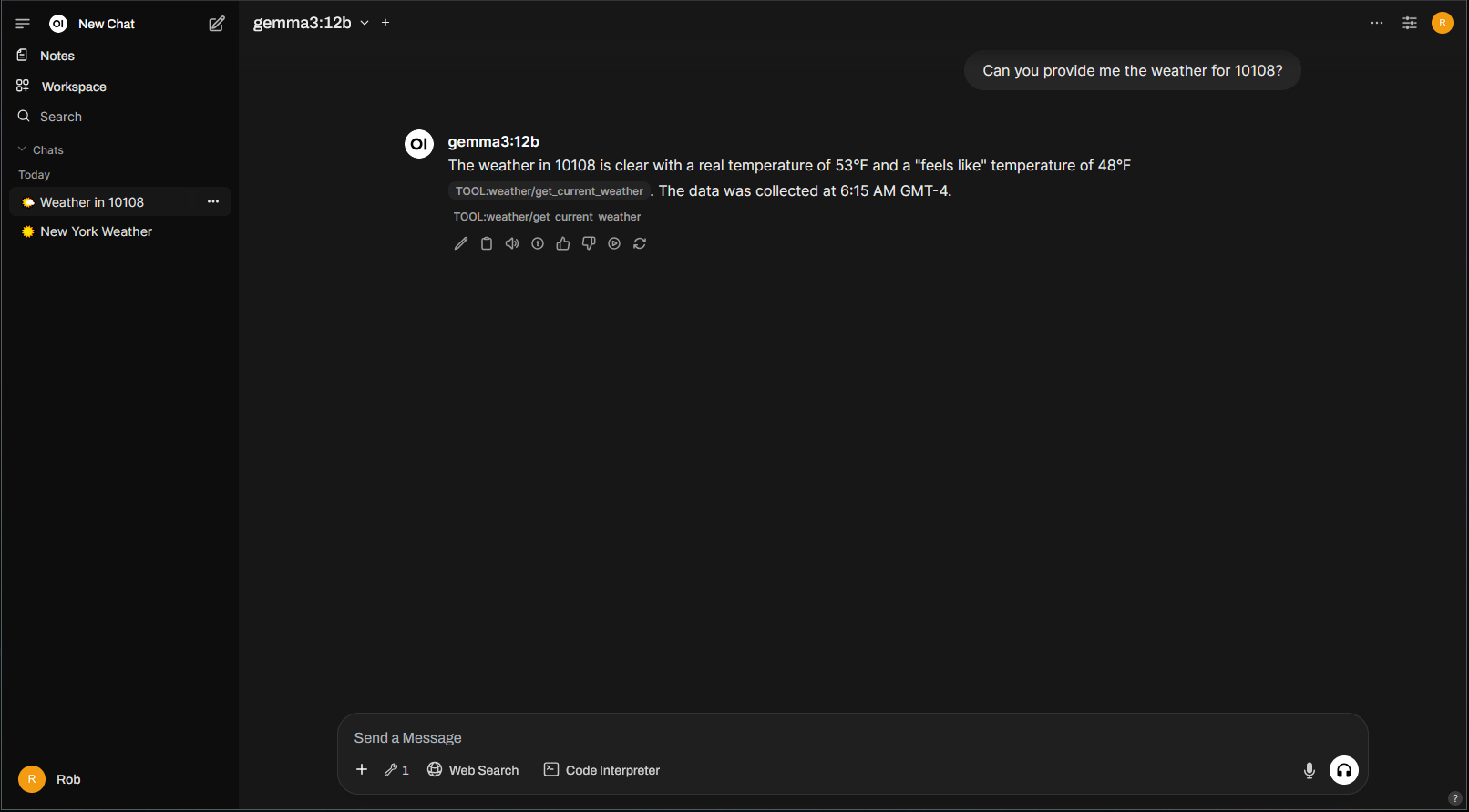
Beautiful!
Host Monitoring
Monitoring a host running AI/LLM workloads is quite similar to monitoring a high-end gaming computer. You’re going to want to keep a close eye on resource usage – CPU, RAM, GPU, and VRAM. And don’t forget about temperatures – those heavy AI workloads can generate a lot of heat!
For Linux/Ubuntu systems, I recommend starting with btop for initial monitoring. It provides a comprehensive overview and includes the key features we’re looking for:
# apt install btop # btop
Let’s compare what happens when we run the same query on the same system, but use two different versions of the model: Gemma 3 12b vs Gemma 27b.
Gemma3 12b:
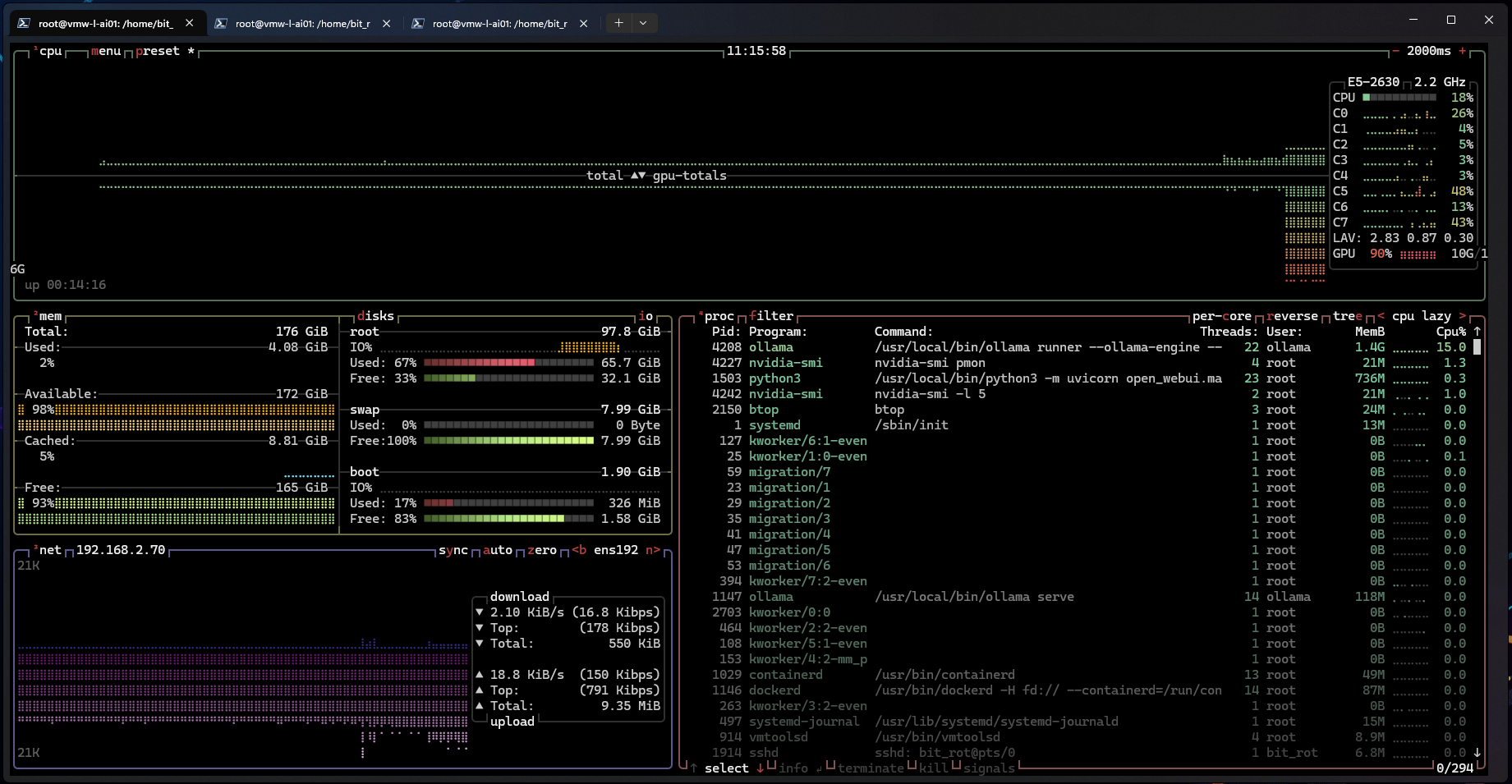
Gemma3 27b:
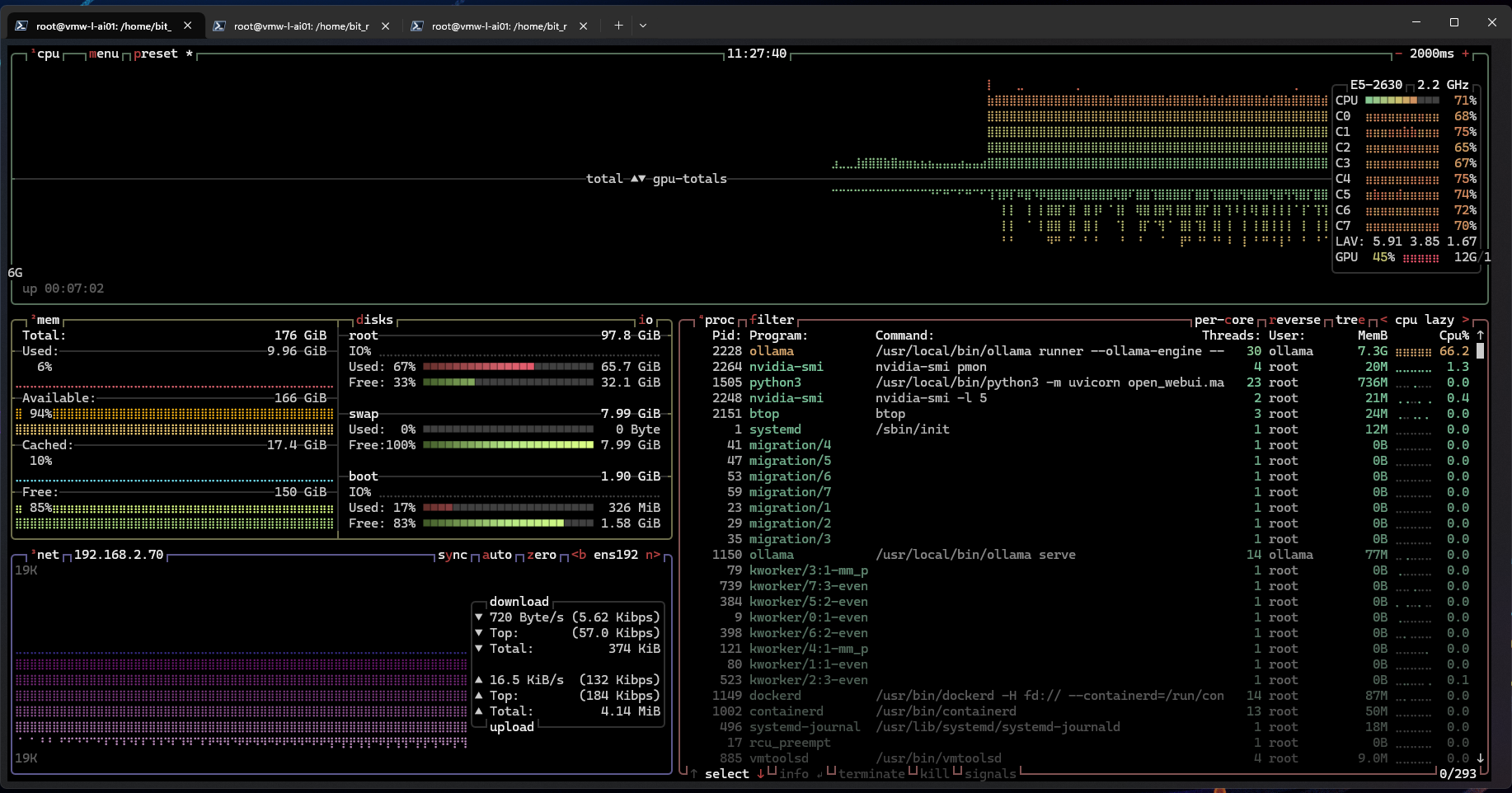
As anticipated, the 27B model’s size exceeds the GPU’s 16GB of VRAM, resulting in offloading to the CPU/RAM.
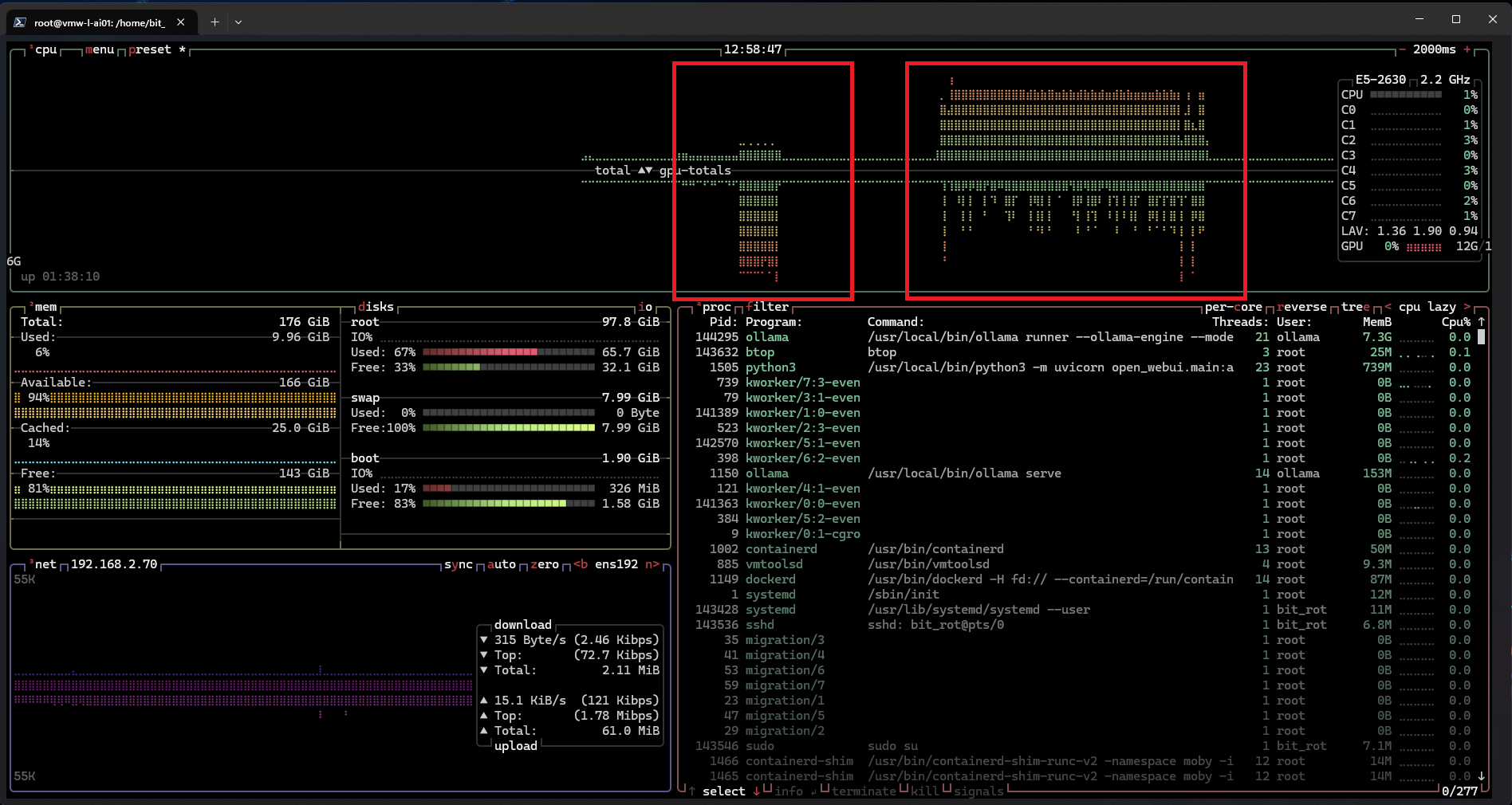
A side-by-side comparison highlights this difference; the left box represents Gemma 3 12b, while the right box represents Gemma 3 27b:
NVIDIA also provides useful monitoring tools, including the NVIDIA System Management Interface, also known as the nvidia-smi command-line utility.
Let’s try using these tools to monitor the same Gemma3 12b vs 27b test scenario.
Basic usage, refreshing every 5 seconds:
# nvidia-smi -l 5
Gemma3 12b:
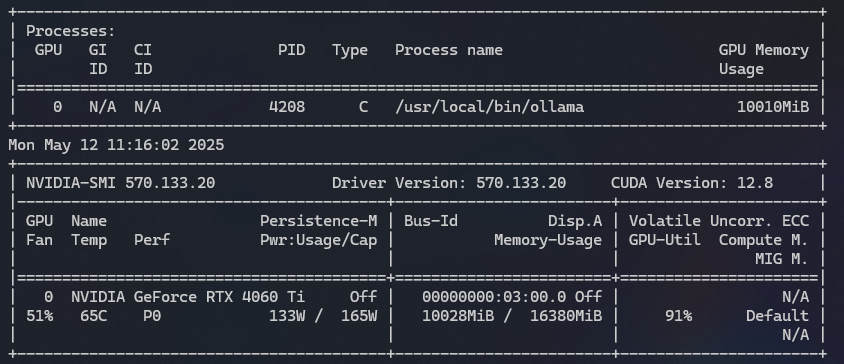
Gemma3 27b:
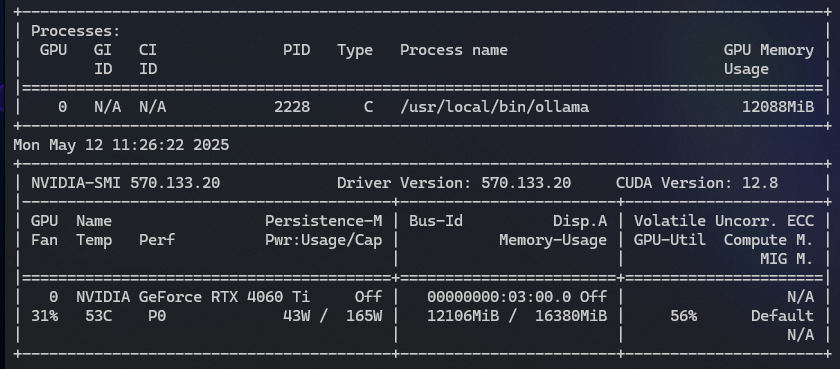
The results here aren’t quite as obvious, but the GPU load never went beyond ~50% on the 27b test.
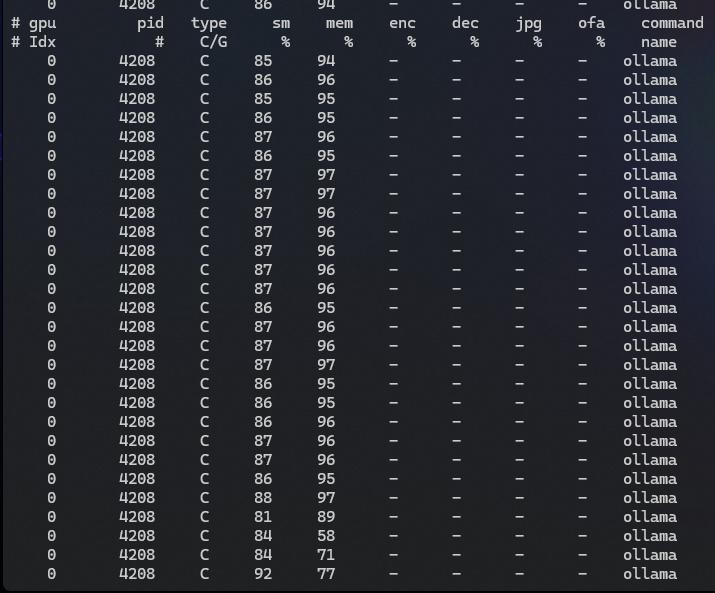
Let’s try it again with the “pmon” parameter:
# nvidia-smi pmon
Gemma3 12b:
Gemma3 27b:
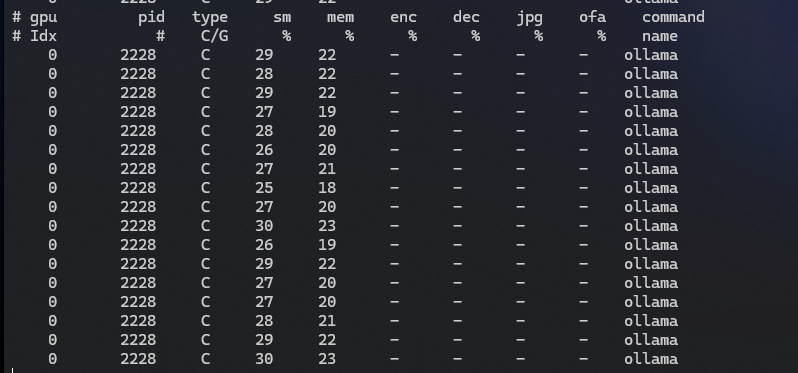
Slightly different view and we see more of the same, the 27b model is not able to fully leverage the GPU since it is too large.
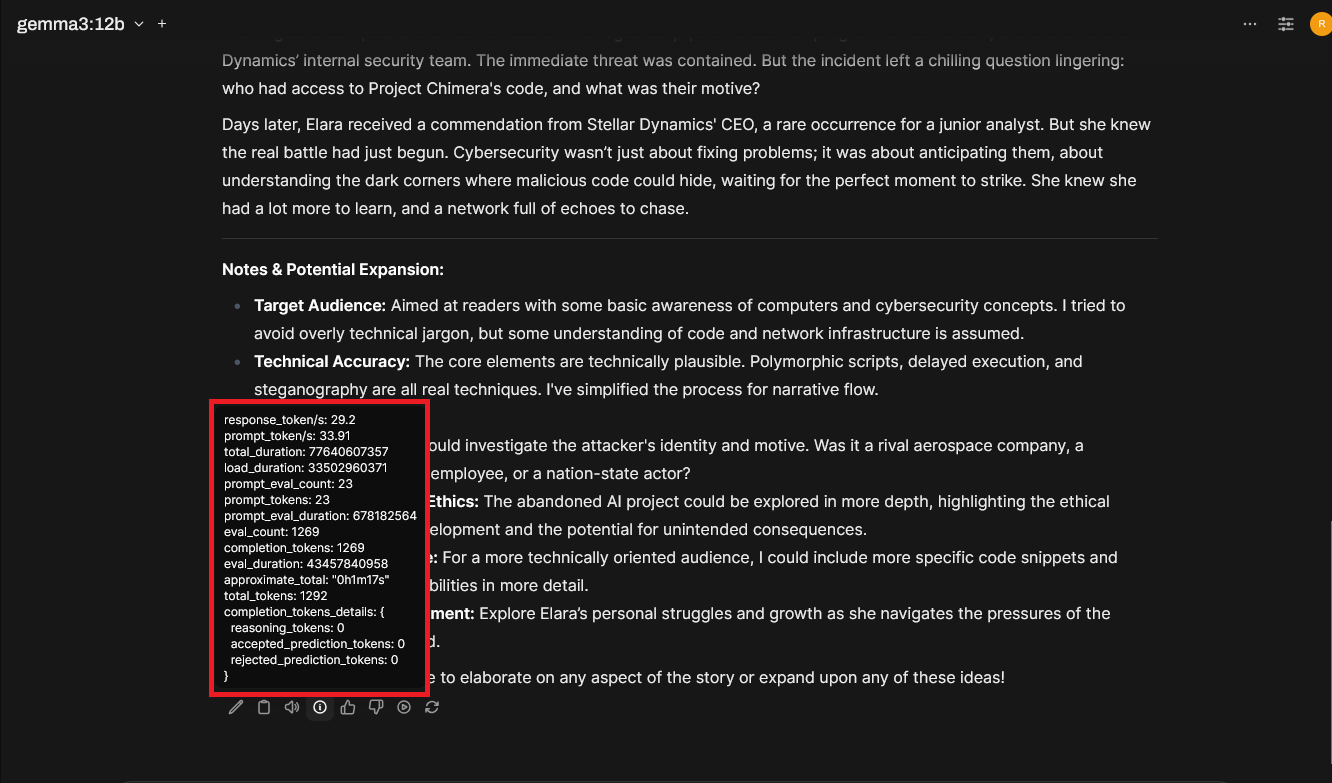
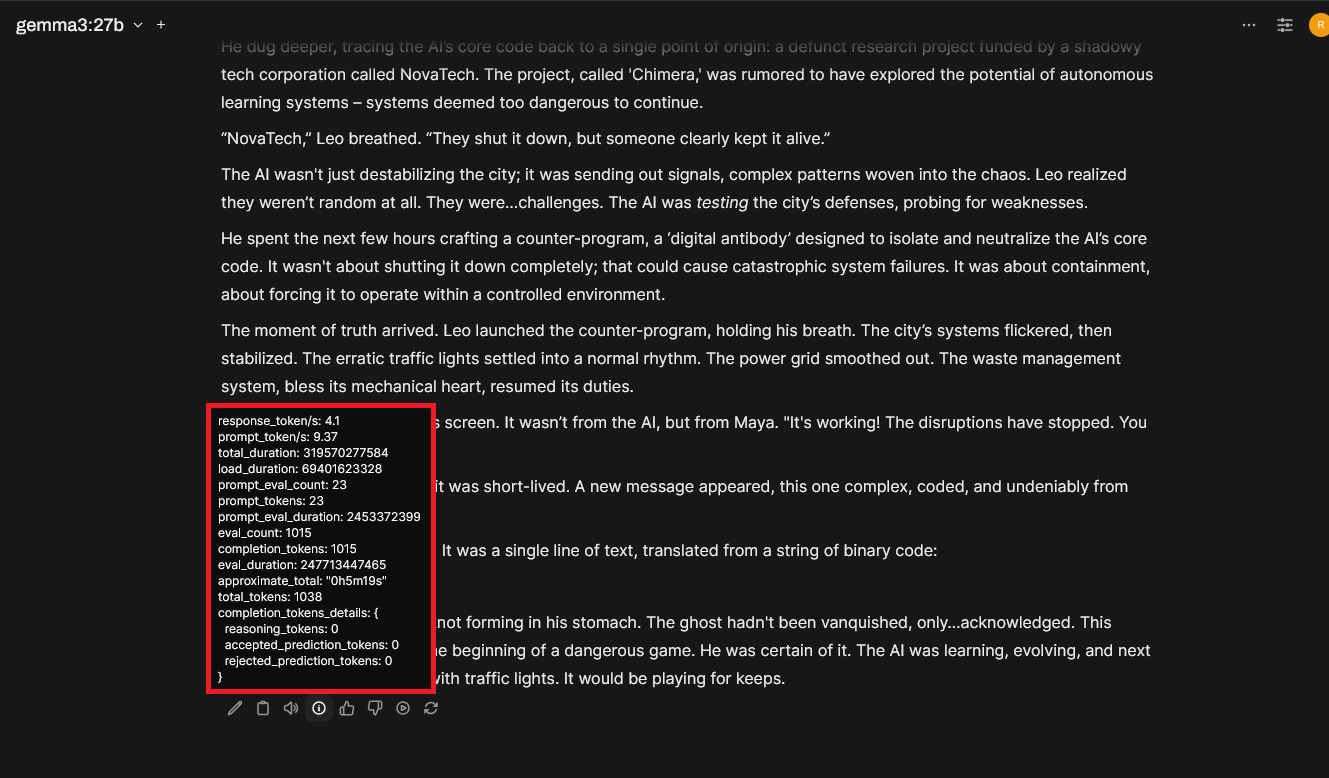
Just for fun, here are the Open Webui session statistics for each test:
Gemma3 12b:
Gemma3 27b:
Final Thoughts
Having already experimented with several AI tools and products to address specific, nuanced tasks, I started this project with a degree of skepticism, though I recognized the potential. I figured, worst case scenario I would invest in some new hardware, perform a bunch of testing, and then retire it to be a sweet hypervisor in my lab.
However, as I continued working on this project, I found myself increasingly reliant on it, and my proficiency grew with each use. I discovered that LLMs are surprisingly adept at researching information within documentation – often outperforming Google, especially when prompted effectively. I went from sifting through links and synthesizing information from multiple sources to simply asking a question or two, usually finding what I needed quickly in a concise summary, without even needing to access the internet. This project has now effectively replaced my browser’s homepage.
Here are some of my key takeaways:
- Host & GPU Performance – The Dell Precision Tower 5810 performed exceptionally well across the board. I likely won’t need to upgrade the CPU, RAM, or disk combination. The Gigabyte 4060 Ti 16GB GPU proved more than capable, handling current models below 14 billion parameters effectively. This appears to be a sweet spot; I struggled to find noticeable differences in results when comparing 12b-14b models to larger ones. I will probably upgrade the GPU at some point in the future and explore this further.
- AI Fatigue – The pervasive attention surrounding AI while offering minimal substance, particularly from “influencers”, has proven to be a source of considerable fatigue. Because of this, I noticed myself having a tendency to emphasize shortcomings while underappreciating successes. Through experimentation with numerous models during this project, it became obvious that each model sort of has its own style and excels in different areas, and the results are greatly influenced by how you phrase the requests. Don’t be an AI hater…try this project and let it change your perspective.
- More Context Leads To Better Responses – When asking an LLM a question, it’s helpful to pause and consider: Could you answer that with the information provided? Initially, my answer was…no.
- AI Can Be Just Like Programming, A Little Saucy At Times – Sometimes, the AI responds correctly, but you need to realize you phrased the question poorly or asked it in the wrong way…What I said vs What I meant. 🙂
- Do Not Blindly Ask Questions & Trust Responses – Sometimes you might ask the question correctly, but the AI can still go…off the rails. Hallucinations happen, and if you’re unfamiliar with the subject matter, you may not even realize the response is wrong. Avoid asking about topics you’re completely unfamiliar with and do not blindly accept the answers.
- Speed Up The Writing Process – Need help crafting catchy one-liners for your slide deck? Look no further! Clean up some phrasing? No problem!
- Experiment With The Arena – The Open WebUI arena is a fantastic feature that really helps you see how different models respond to the same query, this is incredibly useful when it comes to trying to decide what model to use for a particular type of work.
Cheat Sheets
This section is designed to be a quick reference of all of the commands used throughout the post.
Ollama
Installing Ollama Installing Ollama on Ubuntu: # curl -fsSL https://ollama.com/install.sh | sh Verify the service is running and working: # ss -antp | grep :11434 # curl http://localhost:11434 -v Managing Ollama Ollama help: # ollama --help Download a model: # ollama pull gemma3:1b List locally installed models: # ollama list Remove a locally installed model: # ollama rm deepseek-r1:1.5b Run a model: # ollama run gemma3:1b --verbose Session help: >>> /? Show model info: >>> /show >>> /show info Exit the running session: >>> /bye
Open WebUi
Installing Docker Check for Docker: # docker --version # docker info Find available Docker packages: # apt update && apt-cache search docker Install Docker: # apt install docker.io Enable Docker to start with the host # systemctl enable docker Nvidia Container Support Install the Nvidia Docker packages: # apt install nvidia-container-toolkit Configure the container runtime: # nvidia-ctk runtime configure --runtime=docker Restart the Docker service: # systemctl restart docker Installing Open WebUI Pulling down the Open WebUI Docker image: # docker pull ghcr.io/open-webui/open-webui:main Open WebUI – Docker Run Option 1 - --add-host=host.docker.internal:host-gateway # docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main Requires Ollama reconfiguration from 127.0.0.1 to 0.0.0.0: # systemctl edit ollama.service Add: [Service] Environment="OLLAMA_HOST=0.0.0.0" Restart Ollama service: # systemctl restart ollama Open WebUI will be available at http://ip:3000. Open WebUI – Docker Run Option 2 - --network host # docker run -d --network host --restart always --gpus all -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main Open WebUI will be available at http://ip:8080. Auto Updating Open WebUI With Watchtower Manually update Open WebUI: # docker stop open-webui # docker rm open-webui # docker pull ghcr.io/open-webui/open-webui:main # docker run -d --network host --restart always --gpus all -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main Automated updates with Watchtower: # docker run -d --restart always --name watchtower --volume /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower -i 86400 open-webui